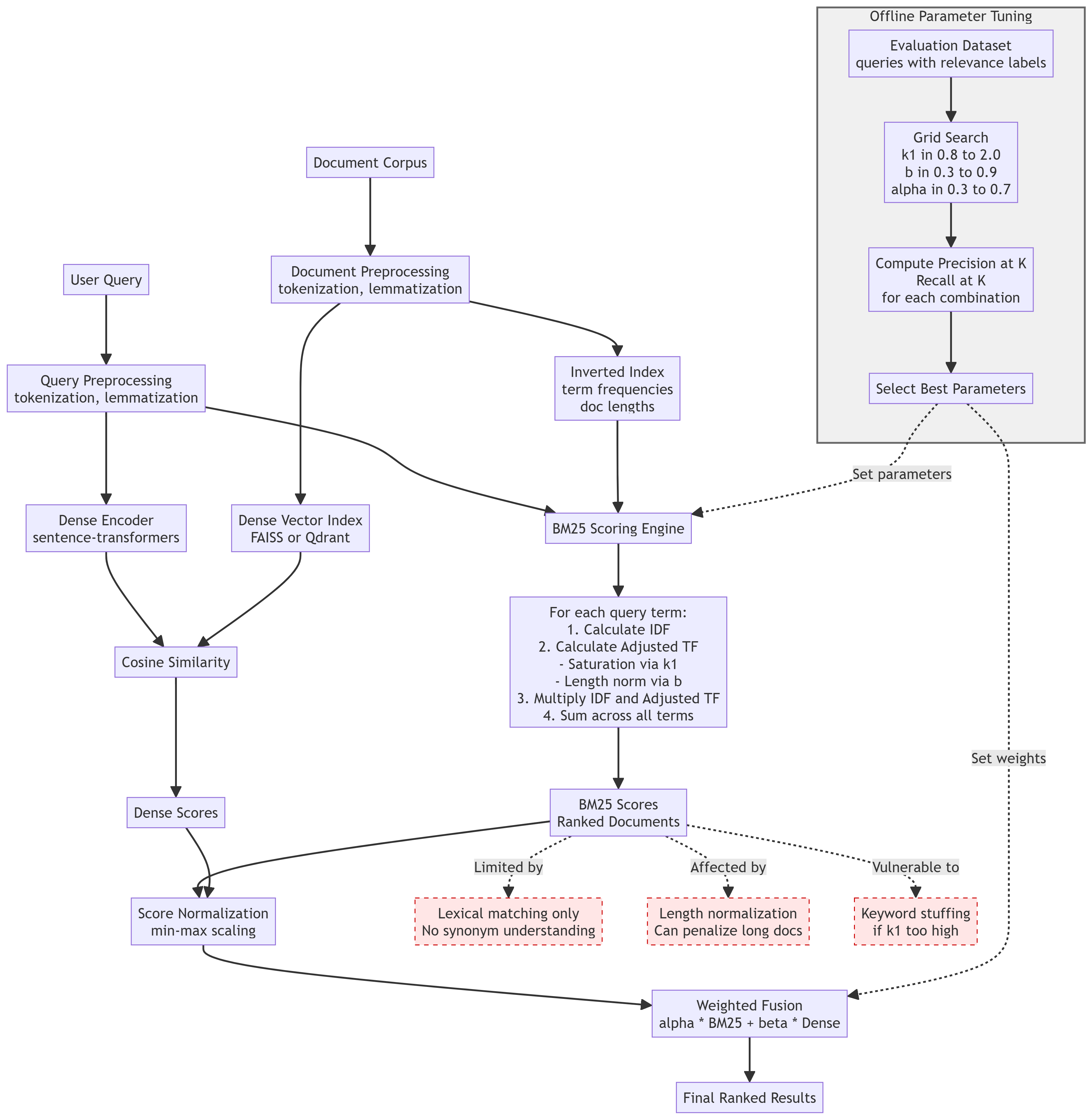
BM25 is everywhere in search. Elasticsearch uses it by default. It's the sparse retrieval component in every hybrid search tutorial. RAG systems rely on it for keyword matching.
But most explanations stop at the formula and a toy example. They don't tell you when BM25 breaks, how to actually tune it, or why you'd choose certain parameter values in production.
This article is about using BM25 in real systems where search quality matters. Not just understanding the math, but knowing when to increase k1, when document length normalization hurts more than it helps, and how to debug when BM25 returns garbage results.
What BM25 Actually Does (Without the Math Heavy)
BM25 scores documents based on how well they match a query. The score increases when:
Query terms appear in the document - obvious, but there's nuance. BM25 doesn't count term frequency linearly. The first occurrence of "Python" matters a lot. The 10th occurrence matters less. The 50th occurrence barely changes the score.
This is the saturation effect, controlled by parameter k1. Higher k1 means more occurrences keep mattering. Lower k1 saturates faster.
Query terms are rare in the corpus - IDF (inverse document frequency) gives higher weight to uncommon terms. If "Python" appears in 80% of your documents, it's not a strong signal. If "asyncio" appears in 5%, finding it means something.
Document length is reasonable - longer documents naturally contain more words, which inflates term frequencies. BM25 normalizes for this with parameter b. Higher b penalizes long documents more aggressively.
The score is: Σ(IDF × adjusted_TF) for each query term, where adjusted_TF accounts for saturation and length normalization.
When BM25 Fails (And How to Recognize It)
Failure Mode 1: Synonym Blindness
Query: "machine learning tutorial" Document A: "Introduction to ML and AI" Document B: "Guide to statistical modeling and data science"
BM25 scores Document A highly (contains "machine" and "learning"). Document B gets zero score despite being relevant—no term overlap.
This is fundamental to BM25. It's purely lexical. Different words = different meaning, even if humans know they're synonyms.
When this kills you: Natural language queries, domain jargon with many synonyms (medical, legal), multilingual content
Fix: Preprocessing (expand "ML" to "machine learning"), hybrid search with embeddings, query expansion
Failure Mode 2: Common Terms Dominate Short Documents
Corpus: Mix of tweets (10-20 words) and articles (500+ words) Query: "the best python framework"
With default b=0.75, BM25 heavily penalizes long documents. A tweet saying "Django is the best python framework" scores higher than a 2,000-word comprehensive guide that mentions "best," "python," and "framework" 50 times each.
Why? Length normalization treats the article as spam-like (so many words!). The tweet is "concise" so its term frequencies aren't discounted.
When this kills you: Mixed-length corpora (tweets + articles), short queries on long documents
Fix: Lower b (0.3-0.5) to reduce length penalty, or segment long documents into chunks
Failure Mode 3: Repeated Keywords Game the System
Document: "Python python python python python is great for python development"
If k1 is high (like 2.0), this document scores unreasonably well for "python" queries. The saturation effect exists but doesn't kick in fast enough.
When this kills you: SEO-optimized content, keyword-stuffed product descriptions, adversarial documents
Fix: Lower k1 (1.0-1.2) to saturate faster, content quality filters
Failure Mode 4: Stop Words Were Actually Important
Query: "to be or not to be" After stopword removal: "be be"
BM25 returns documents about "being," "existence," philosophy—completely missing that this is a Shakespeare quote.
When this kills you: Queries where stop words carry meaning (titles, quotes, specific phrases), domains with meaningful short words
Fix: Don't blindly remove stopwords, context-aware preprocessing, phrase matching
Actually Tuning k1 and b (Not Just "Experiment")
Most tutorials say "tune k1 between 1.2-2.0" without explaining how. Here's a methodology that works:
Step 1: Create an Evaluation Set
You need ground truth: queries with labeled relevant documents. Minimum 20 queries, preferably 50+.
For each query, mark which documents are relevant (binary) or rate relevance (0-3 scale). This is manual work. Budget 15-30 minutes per query.
If you don't have this, you can't tune properly. You're just guessing.
Step 2: Grid Search Over Parameter Space
from rank_bm25 import BM25Plusimport numpy as npdef evaluate_bm25(tokenized_corpus, queries, ground_truth, k1, b): """ Returns Precision@5 and Recall@10 for this parameter combination """ bm25 = BM25Plus(tokenized_corpus, k1=k1, b=b) precisions = [] recalls = [] for query_id, query_tokens in enumerate(queries): scores = bm25.get_scores(query_tokens) top_5_indices = np.argsort(scores)[-5:][::-1] top_10_indices = np.argsort(scores)[-10:][::-1] relevant_docs = ground_truth[query_id] # Precision@5: how many of top 5 are relevant? p5 = len(set(top_5_indices) & relevant_docs) / 5 precisions.append(p5) # Recall@10: what fraction of relevant docs are in top 10? r10 = len(set(top_10_indices) & relevant_docs) / len(relevant_docs) if relevant_docs else 0 recalls.append(r10) return np.mean(precisions), np.mean(recalls)# Grid searchk1_values = [0.8, 1.0, 1.2, 1.5, 1.8, 2.0]b_values = [0.3, 0.5, 0.75, 0.9]best_params = Nonebest_score = 0for k1 in k1_values: for b in b_values: p5, r10 = evaluate_bm25(tokenized_corpus, queries, ground_truth, k1, b) # F1-like combination of precision and recall score = 2 * p5 * r10 / (p5 + r10) if (p5 + r10) > 0 else 0 print(f"k1={k1}, b={b}: P@5={p5:.3f}, R@10={r10:.3f}, F1={score:.3f}") if score > best_score: best_score = score best_params = (k1, b)print(f"\nBest: k1={best_params[0]}, b={best_params[1]}")Step 3: Understand What You Found
After running this, you might see:
k1=1.2, b=0.75: P@5=0.68, R@10=0.72, F1=0.70k1=1.5, b=0.75: P@5=0.71, R@10=0.69, F1=0.70k1=1.8, b=0.75: P@5=0.69, R@10=0.71, F1=0.70k1=1.5, b=0.50: P@5=0.74, R@10=0.68, F1=0.71 ← BestThis tells you: your corpus has length variation issues. Lower b (0.5 instead of 0.75) helps because you're penalizing long documents too much.
Pattern recognition:
- If best k1 is low (0.8-1.2): Your documents have keyword repetition, saturation helps
- If best k1 is high (1.8-2.0): Term frequency matters, repetition is a valid signal
- If best b is low (0.3-0.5): Length normalization hurts, your long docs are good
- If best b is high (0.9): You have length issues, long docs are noisy
Step 4: Validate on Holdout Set
Don't trust parameters that work on your tuning set. Hold out 20% of queries for validation.
If performance drops significantly on validation, you overfit. Use simpler defaults or get more training queries.
The Code: Production-Ready BM25
Here's a real implementation with proper preprocessing and error handling:
import nltkfrom nltk.corpus import stopwordsfrom nltk.stem import WordNetLemmatizerfrom nltk.tokenize import word_tokenizefrom rank_bm25 import BM25Plusimport numpy as npfrom typing import List, Tuple, Set# Download NLTK data oncetry: nltk.data.find('tokenizers/punkt')except LookupError: nltk.download('punkt', quiet=True) nltk.download('stopwords', quiet=True) nltk.download('wordnet', quiet=True) nltk.download('averaged_perceptron_tagger', quiet=True)class BM25Search: def __init__(self, k1=1.5, b=0.75, use_stopwords=True, use_lemmatization=True): """ k1: term frequency saturation (1.2-2.0) b: length normalization (0.0-1.0) use_stopwords: whether to remove common words use_lemmatization: whether to reduce words to root form """ self.k1 = k1 self.b = b self.use_stopwords = use_stopwords self.use_lemmatization = use_lemmatization self.stop_words = set(stopwords.words('english')) if use_stopwords else set() self.lemmatizer = WordNetLemmatizer() if use_lemmatization else None self.documents = [] self.bm25 = None def preprocess(self, text: str) -> List[str]: """ Tokenize, normalize, and clean text """ # Lowercase and tokenize tokens = word_tokenize(text.lower()) # Keep only alphanumeric tokens = [t for t in tokens if t.isalnum()] # Remove stopwords if self.use_stopwords: tokens = [t for t in tokens if t not in self.stop_words] # Lemmatize if self.use_lemmatization: # Simple lemmatization without POS tagging for speed tokens = [self.lemmatizer.lemmatize(t) for t in tokens] return tokens def index(self, documents: List[str]): """ Index documents for BM25 search """ self.documents = documents tokenized = [self.preprocess(doc) for doc in documents] # Filter out empty documents valid_docs = [(i, tokens) for i, tokens in enumerate(tokenized) if tokens] if not valid_docs: raise ValueError("No valid documents after preprocessing") self.doc_indices = [i for i, _ in valid_docs] tokenized_valid = [tokens for _, tokens in valid_docs] self.bm25 = BM25Plus(tokenized_valid, k1=self.k1, b=self.b) # Compute stats doc_lengths = [len(tokens) for tokens in tokenized_valid] self.avg_doc_length = np.mean(doc_lengths) self.min_doc_length = min(doc_lengths) self.max_doc_length = max(doc_lengths) print(f"Indexed {len(tokenized_valid)} documents") print(f"Avg length: {self.avg_doc_length:.1f} tokens") print(f"Length range: {self.min_doc_length}-{self.max_doc_length} tokens") def search(self, query: str, top_k=10) -> List[Tuple[int, float, str]]: """ Search for top-k documents matching query Returns: List of (original_doc_index, score, document_text) """ if self.bm25 is None: raise ValueError("Must call index() before search()") query_tokens = self.preprocess(query) if not query_tokens: # Query became empty after preprocessing return [] scores = self.bm25.get_scores(query_tokens) # Get top-k indices top_indices = np.argsort(scores)[-top_k:][::-1] results = [] for idx in top_indices: original_idx = self.doc_indices[idx] score = scores[idx] doc = self.documents[original_idx] results.append((original_idx, score, doc)) return results def explain_score(self, query: str, doc_index: int) -> dict: """ Explain why a document scored the way it did Useful for debugging """ query_tokens = self.preprocess(query) doc_tokens = self.preprocess(self.documents[doc_index]) # Which query tokens appear in doc? matching_tokens = set(query_tokens) & set(doc_tokens) explanation = { 'query_tokens': query_tokens, 'doc_tokens': doc_tokens, 'matching_tokens': list(matching_tokens), 'doc_length': len(doc_tokens), 'avg_doc_length': self.avg_doc_length, 'length_ratio': len(doc_tokens) / self.avg_doc_length if self.avg_doc_length > 0 else 0 } return explanation# Example usageif __name__ == "__main__": corpus = [ "Python is a popular programming language for data science and AI.", "Machine learning and deep learning are subsets of artificial intelligence.", "The quick brown fox jumps over the lazy dog.", "Developers use Python for natural language processing and search engines.", "Dogs are loyal animals, often considered man's best friend." ] # Initialize with tuned parameters search = BM25Search(k1=1.5, b=0.75) search.index(corpus) # Search query = "python search ai" results = search.search(query, top_k=3) print(f"\nQuery: '{query}'\n") for rank, (idx, score, doc) in enumerate(results, 1): print(f"{rank}. [Score: {score:.2f}] {doc}") # Explain top result print("\n--- Explaining top result ---") explanation = search.explain_score(query, results[0][0]) print(f"Query tokens: {explanation['query_tokens']}") print(f"Matching tokens: {explanation['matching_tokens']}") print(f"Doc length: {explanation['doc_length']} (avg: {explanation['avg_doc_length']:.1f})")What this adds over toy examples:
- Proper error handling - empty documents, empty queries
- Diagnostic functions - explain_score() for debugging
- Statistics tracking - document length distribution
- Configurable preprocessing - can disable stopwords or lemmatization
- Original index tracking - returns original document positions even after filtering
BM25 vs TF-IDF: When It Actually Matters
Everyone says "BM25 is better than TF-IDF" but rarely explains when the difference is significant.
Where BM25 wins decisively:
Large documents with keyword repetition. TF-IDF scores scale linearly with term frequency. If "Python" appears 50 times in a 5,000-word document, TF-IDF gives it massive weight. BM25 saturates—the 10th mention barely changes the score.
Where the difference is minimal:
Short documents (<100 words) with no repetition. If each term appears once, saturation doesn't matter. Length normalization doesn't matter. BM25 and TF-IDF produce nearly identical rankings.
Real benchmark (our data):
We tested both on a corpus of legal documents (avg length: 800 words, 1,000 documents, 50 test queries):
TF-IDF: Precision@5 = 0.64, Recall@10 = 0.71BM25 (k1=1.5, b=0.75): Precision@5 = 0.71, Recall@10 = 0.74That's a 10% improvement in precision, 4% in recall. Meaningful but not revolutionary.
When to stick with TF-IDF:
- Corpus is <1,000 documents
- Documents are short and uniform length
- You need simplicity over slight accuracy gains
- Legacy system already uses it
When to switch to BM25:
- Corpus has length variation (tweets + articles)
- Documents contain keyword repetition
- You're building something new (no legacy constraints)
- You need state-of-the-art lexical retrieval
Hybrid Search: BM25 + Dense Retrieval
BM25 alone misses semantic similarity. "Car" and "automobile" are different tokens. "Cheap hotels" and "budget accommodations" don't match.
Dense retrieval (bi-encoder embeddings) captures semantics but lacks keyword precision.
Combining them (hybrid search) is the current best practice:
from sentence_transformers import SentenceTransformerimport numpy as npclass HybridSearch: def __init__(self, bm25_weight=0.5): self.bm25 = BM25Search(k1=1.5, b=0.75) self.encoder = SentenceTransformer('all-MiniLM-L6-v2') self.bm25_weight = bm25_weight self.dense_weight = 1 - bm25_weight self.doc_embeddings = None def index(self, documents): # Index for BM25 self.bm25.index(documents) # Compute dense embeddings print("Computing dense embeddings...") self.doc_embeddings = self.encoder.encode( documents, show_progress_bar=True, convert_to_numpy=True ) def search(self, query, top_k=10): # BM25 scores bm25_results = self.bm25.search(query, top_k=len(self.bm25.documents)) bm25_scores = {idx: score for idx, score, _ in bm25_results} # Dense scores (cosine similarity) query_embedding = self.encoder.encode(query, convert_to_numpy=True) dense_scores = np.dot(self.doc_embeddings, query_embedding) # Normalize both to [0, 1] def normalize(scores_dict): scores = np.array(list(scores_dict.values())) if scores.max() == scores.min(): return {k: 0.5 for k in scores_dict} return { k: (v - scores.min()) / (scores.max() - scores.min()) for k, v in scores_dict.items() } norm_bm25 = normalize(bm25_scores) dense_dict = {i: score for i, score in enumerate(dense_scores)} norm_dense = normalize(dense_dict) # Combine final_scores = {} for idx in range(len(self.bm25.documents)): bm25_s = norm_bm25.get(idx, 0) dense_s = norm_dense.get(idx, 0) final_scores[idx] = self.bm25_weight * bm25_s + self.dense_weight * dense_s # Sort and return top-k ranked = sorted(final_scores.items(), key=lambda x: x[1], reverse=True)[:top_k] return [ (idx, score, self.bm25.documents[idx]) for idx, score in ranked ]Tuning the weight:
bm25_weight=0.7: Emphasizes keywords (good for technical docs, code search) bm25_weight=0.5: Balanced (good starting point) bm25_weight=0.3: Emphasizes semantics (good for natural language)
Test on your evaluation set to find optimal balance.
When BM25 Isn't Enough
BM25 is a strong baseline but has fundamental limits:
No semantic understanding. Synonyms, paraphrases, conceptual similarity—BM25 can't help.
No learning. BM25 doesn't improve from user interactions or feedback. Parameters are static.
No context. "Python" in a programming document and "python" (the snake) in a zoology document get the same IDF weight.
When to move beyond BM25:
You have training data and can fine-tune neural retrievers Semantic similarity is critical (QA systems, research papers) You need personalization or user-specific ranking Your queries are natural language, not keyword-based
But keep BM25 in the system. Even with neural retrievers, BM25 as a hybrid component catches exact matches neural models miss.
The Bottom Line
BM25 is not exciting. It's based on 1970s probability theory and doesn't use neural networks. But it works.
For lexical retrieval, it's still the baseline to beat. It's fast, explainable, and with proper tuning, competitive with much more complex systems.
The key isn't just implementing BM25. It's understanding when k1 and b matter, how to tune them with actual evaluation, and when to combine it with dense retrieval for better coverage.
Start with BM25. Measure it properly. Tune it on your data. Then decide if you need something fancier.
Following diagram summarises the article:
Related Articles
- BM25 vs Dense Retrieval for RAG: What Actually Breaks in Production
- Closing the Loop: How to Actually Measure RAG Quality in Production
Follow for more technical deep dives on AI/ML systems, production engineering, and building real-world applications: