1. Introduction
Modern agentic AI systems behave less like monolithic LLM applications and more like distributed, autonomous workers making decisions, invoking tools, coordinating tasks, and reacting to events. This autonomy introduces unpredictable timing, variable workloads, and long-running operations—all of which traditional synchronous architectures struggle to handle.
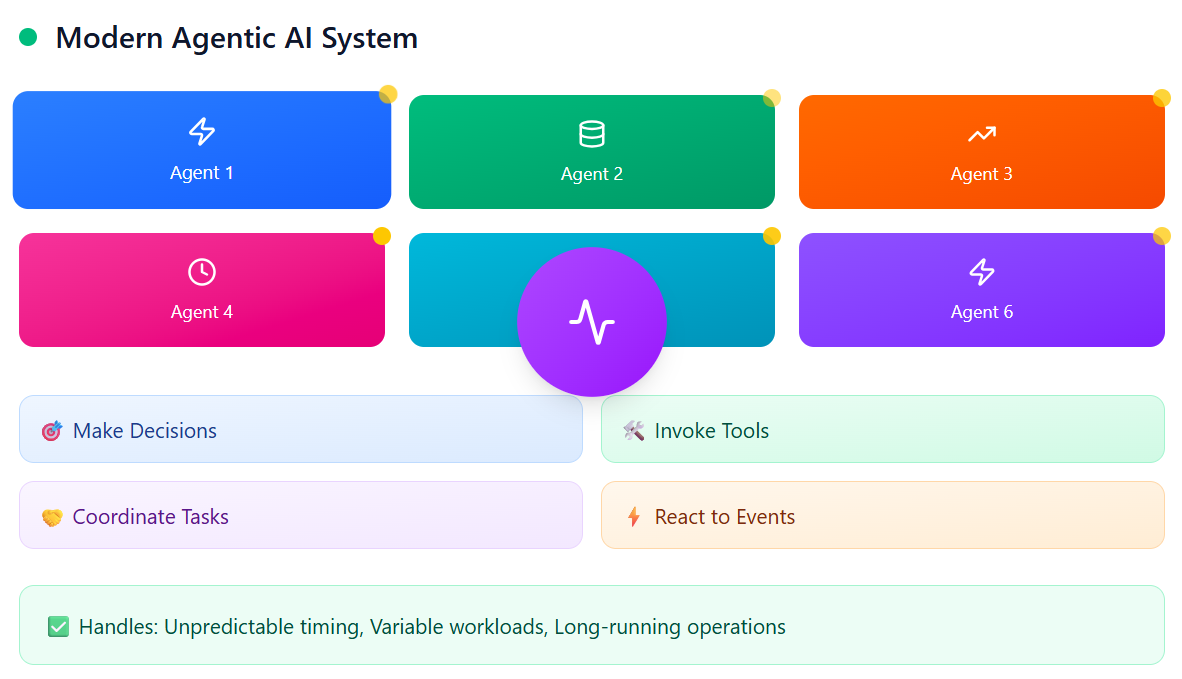
Figure 1: Modern Agentic AI Systems
Asynchronous processing and message queues solve these problems elegantly. They allow agentic AI systems to scale, stay responsive, and coordinate multiple agents working in parallel. Let’s break down how they do this.
2. Core Architectural Roles of Async & Queues
2.1 Handling Long-Running Agent Operations
Agentic AI workflows often include:
-
multiple LLM calls
-
tool invocation chains
-
web scraping
-
data extraction
-
reasoning loops
-
reflection cycles
These tasks can take anywhere from a few seconds to several minutes.
If executed synchronously:
-
user requests block
-
system threads get stuck
-
timeouts become common
-
overall throughput collapses
Async + Queues Fix This
The main thread:
-
accepts the request
-
places it in a queue
-
immediately responds with a task ID
Meanwhile, workers execute the long-running agent task independently.
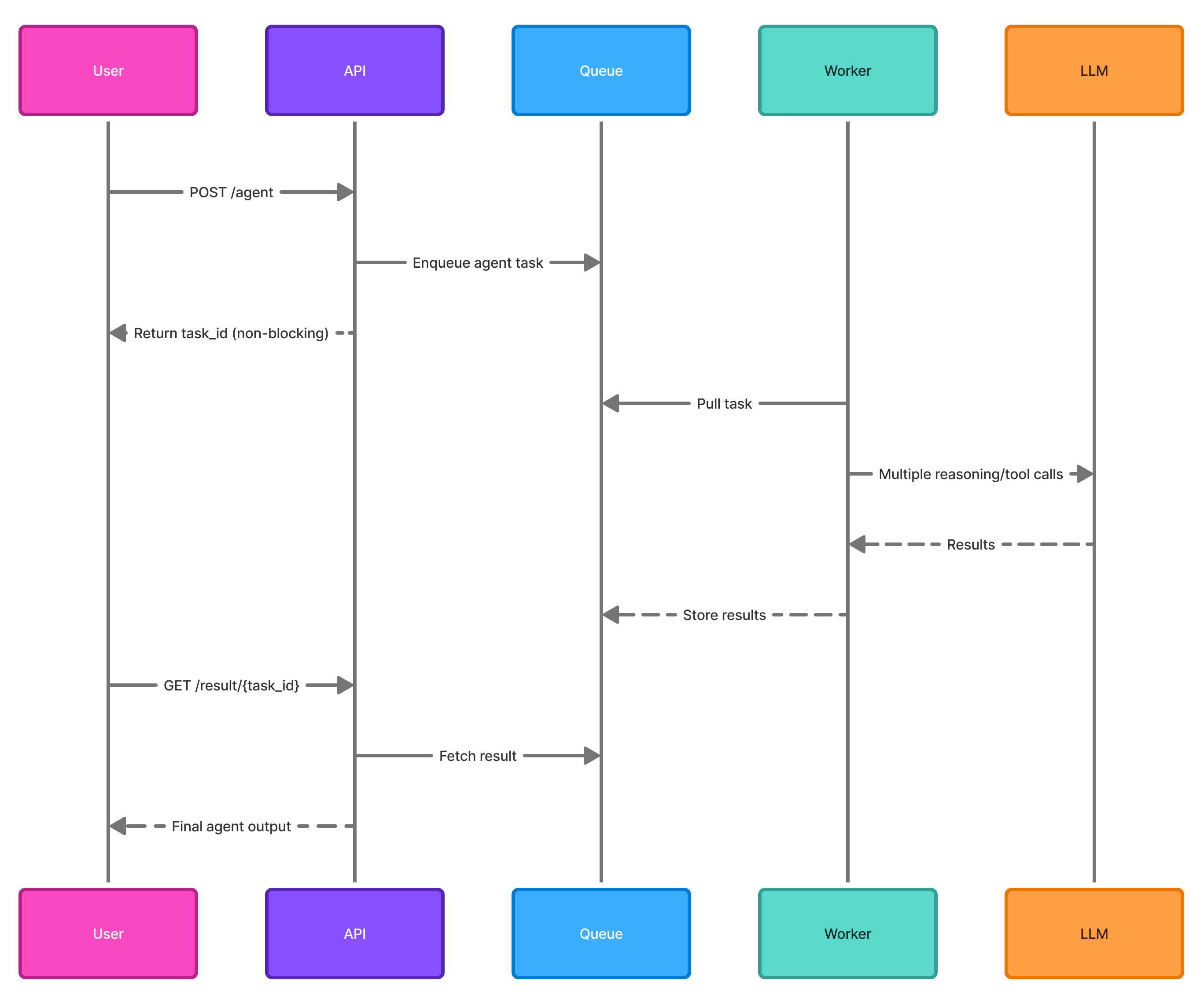
Figure 2: Diagram — Long-running agent tasks using async workers
2.2 Basic Async Agent Task with Celery
Key Features Demonstrated:
-
✅ Non-blocking task submission
-
✅ Progress tracking with state updates
-
✅ Automatic retry logic with exponential backoff
-
✅ Timeout protection
-
✅ RESTful API integration
-
✅ Task result retrieval
# tasks.py - Define async agent tasksfrom celery import Celeryfrom typing import Dict, Anyimport timefrom openai import OpenAI<div></div># Initialize Celery with Redis as brokerapp = Celery('agentic_tasks', broker='redis://localhost:6379/0', backend='redis://localhost:6379/0')<div></div># Configure task settingsapp.conf.update( task_serializer='json', accept_content=['json'], result_serializer='json', timezone='UTC', enable_utc=True, task_track_started=True, task_time_limit=3600, # 1 hour max task_soft_time_limit=3300, # Warning at 55 minutes)<div></div>@app.task(bind=True, max_retries=3)def execute_agent_workflow(self, query: str, context: Dict[str, Any]) -> Dict[str, Any]: """ Execute a long-running agent workflow asynchronously. Args: query: User's query or task context: Additional context for the agent Returns: Dict containing agent's response and metadata """ try: # Update task state to indicate progress self.update_state( state='PROCESSING', meta={'step': 'initializing', 'progress': 10} ) # Initialize LLM client client = OpenAI() # Step 1: Initial reasoning self.update_state( state='PROCESSING', meta={'step': 'reasoning', 'progress': 25} ) reasoning_response = client.chat.completions.create( model="gpt-4", messages=[ {"role": "system", "content": "You are a helpful research agent."}, {"role": "user", "content": f"Analyze this query: {query}"} ], timeout=60 ) # Step 2: Tool invocation (simulated) self.update_state( state='PROCESSING', meta={'step': 'tool_execution', 'progress': 50} ) # Simulate web scraping or API calls time.sleep(2) tool_results = {"data": "scraped content"} # Step 3: Final synthesis self.update_state( state='PROCESSING', meta={'step': 'synthesis', 'progress': 75} ) final_response = client.chat.completions.create( model="gpt-4", messages=[ {"role": "system", "content": "Synthesize the findings."}, {"role": "user", "content": f"Results: {tool_results}"} ], timeout=60 ) # Complete self.update_state( state='SUCCESS', meta={'step': 'complete', 'progress': 100} ) return { 'status': 'success', 'result': final_response.choices[0].message.content, 'metadata': { 'reasoning': reasoning_response.choices[0].message.content, 'tools_used': ['web_search', 'scraper'] } } except Exception as exc: # Retry with exponential backoff self.update_state( state='FAILURE', meta={'error': str(exc)} ) raise self.retry(exc=exc, countdown=60 * (2 ** self.request.retries))# tasks.py - Define async agent tasksfrom celery import Celeryfrom typing import Dict, Anyimport timefrom openai import OpenAI# Initialize Celery with Redis as brokerapp = Celery('agentic_tasks', broker='redis://localhost:6379/0', backend='redis://localhost:6379/0')# Configure task settingsapp.conf.update( task_serializer='json', accept_content=['json'], result_serializer='json', timezone='UTC', enable_utc=True, task_track_started=True, task_time_limit=3600, # 1 hour max task_soft_time_limit=3300, # Warning at 55 minutes)@app.task(bind=True, max_retries=3)def execute_agent_workflow(self, query: str, context: Dict[str, Any]) -> Dict[str, Any]: """ Execute a long-running agent workflow asynchronously. Args: query: User's query or task context: Additional context for the agent Returns: Dict containing agent's response and metadata """ try: # Update task state to indicate progress self.update_state( state='PROCESSING', meta={'step': 'initializing', 'progress': 10} ) # Initialize LLM client client = OpenAI() # Step 1: Initial reasoning self.update_state( state='PROCESSING', meta={'step': 'reasoning', 'progress': 25} ) reasoning_response = client.chat.completions.create( model="gpt-4", messages=[ {"role": "system", "content": "You are a helpful research agent."}, {"role": "user", "content": f"Analyze this query: {query}"} ], timeout=60 ) # Step 2: Tool invocation (simulated) self.update_state( state='PROCESSING', meta={'step': 'tool_execution', 'progress': 50} ) # Simulate web scraping or API calls time.sleep(2) tool_results = {"data": "scraped content"} # Step 3: Final synthesis self.update_state( state='PROCESSING', meta={'step': 'synthesis', 'progress': 75} ) final_response = client.chat.completions.create( model="gpt-4", messages=[ {"role": "system", "content": "Synthesize the findings."}, {"role": "user", "content": f"Results: {tool_results}"} ], timeout=60 ) # Complete self.update_state( state='SUCCESS', meta={'step': 'complete', 'progress': 100} ) return { 'status': 'success', 'result': final_response.choices[0].message.content, 'metadata': { 'reasoning': reasoning_response.choices[0].message.content, 'tools_used': ['web_search', 'scraper'] } } except Exception as exc: # Retry with exponential backoff self.update_state( state='FAILURE', meta={'error': str(exc)} ) raise self.retry(exc=exc, countdown=60 * (2 ** self.request.retries))# API endpoint integration# api.pyfrom fastapi import FastAPI, BackgroundTasksfrom pydantic import BaseModelfrom celery.result import AsyncResult<div></div>app_api = FastAPI()<div></div>class AgentRequest(BaseModel): query: str context: dict = {}<div></div>class TaskResponse(BaseModel): task_id: str status: str message: str<div></div>@app_api.post("/agent/execute", response_model=TaskResponse)async def execute_agent(request: AgentRequest): """ Submit agent task to queue and return immediately. """ # Enqueue the task task = execute_agent_workflow.delay( query=request.query, context=request.context ) return TaskResponse( task_id=task.id, status="queued", message=f"Task submitted. Check status at /agent/status/{task.id}" )<div></div>@app_api.get("/agent/status/{task_id}")async def get_agent_status(task_id: str): """ Check the status of a running agent task. """ task_result = AsyncResult(task_id, app=app) if task_result.state == 'PENDING': response = { 'task_id': task_id, 'state': task_result.state, 'status': 'Task is waiting in queue...' } elif task_result.state == 'PROCESSING': response = { 'task_id': task_id, 'state': task_result.state, 'progress': task_result.info.get('progress', 0), 'current_step': task_result.info.get('step', 'unknown') } elif task_result.state == 'SUCCESS': response = { 'task_id': task_id, 'state': task_result.state, 'result': task_result.result } else: # Something went wrong response = { 'task_id': task_id, 'state': task_result.state, 'error': str(task_result.info) } return response<div></div>@app_api.get("/agent/result/{task_id}")async def get_agent_result(task_id: str): """ Retrieve the final result of a completed agent task. """ task_result = AsyncResult(task_id, app=app) if not task_result.ready(): return { 'task_id': task_id, 'status': 'not_ready', 'message': 'Task is still processing' } return { 'task_id': task_id, 'status': 'complete', 'result': task_result.get() }# API endpoint integration# api.pyfrom fastapi import FastAPI, BackgroundTasksfrom pydantic import BaseModelfrom celery.result import AsyncResultapp_api = FastAPI()class AgentRequest(BaseModel): query: str context: dict = {}class TaskResponse(BaseModel): task_id: str status: str message: str@app_api.post("/agent/execute", response_model=TaskResponse)async def execute_agent(request: AgentRequest): """ Submit agent task to queue and return immediately. """ # Enqueue the task task = execute_agent_workflow.delay( query=request.query, context=request.context ) return TaskResponse( task_id=task.id, status="queued", message=f"Task submitted. Check status at /agent/status/{task.id}" )@app_api.get("/agent/status/{task_id}")async def get_agent_status(task_id: str): """ Check the status of a running agent task. """ task_result = AsyncResult(task_id, app=app) if task_result.state == 'PENDING': response = { 'task_id': task_id, 'state': task_result.state, 'status': 'Task is waiting in queue...' } elif task_result.state == 'PROCESSING': response = { 'task_id': task_id, 'state': task_result.state, 'progress': task_result.info.get('progress', 0), 'current_step': task_result.info.get('step', 'unknown') } elif task_result.state == 'SUCCESS': response = { 'task_id': task_id, 'state': task_result.state, 'result': task_result.result } else: # Something went wrong response = { 'task_id': task_id, 'state': task_result.state, 'error': str(task_result.info) } return response@app_api.get("/agent/result/{task_id}")async def get_agent_result(task_id: str): """ Retrieve the final result of a completed agent task. """ task_result = AsyncResult(task_id, app=app) if not task_result.ready(): return { 'task_id': task_id, 'status': 'not_ready', 'message': 'Task is still processing' } return { 'task_id': task_id, 'status': 'complete', 'result': task_result.get() }2.3 Managing Concurrent Multi-Agent Behavior
In agentic ecosystems, you often have many agents working at once:
-
Research agent
-
Scraper agent
-
Reviewer agent
-
Planner agent
-
Tool agent
Without queues, simultaneous operations could overwhelm:
-
LLM API rate limits
-
vector database
-
external APIs
-
CPU-bound local inference
Queues allow:
-
throttling
-
prioritization
-
buffering
-
safe parallel execution
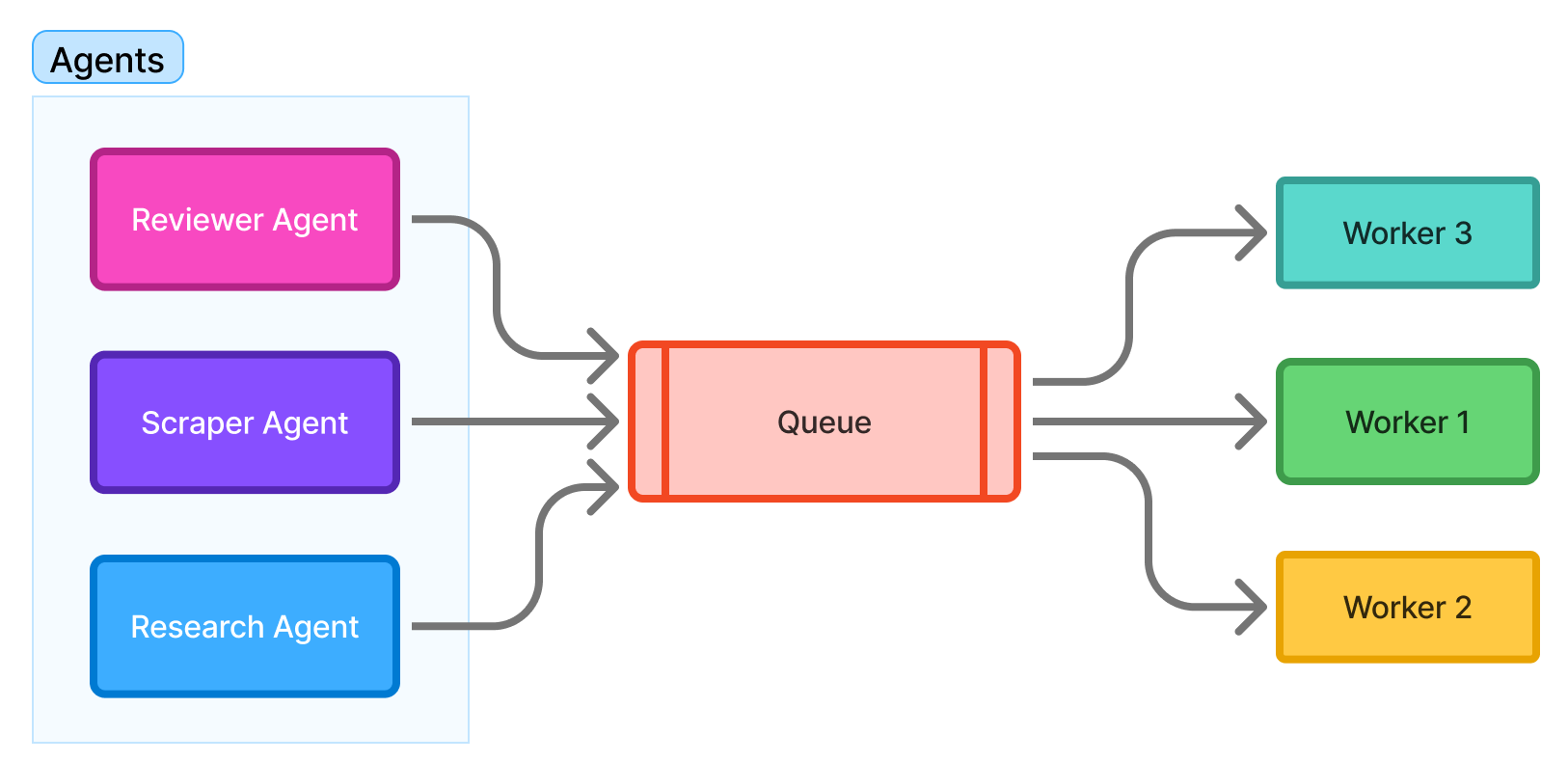
Figure 3: Diagram — Multi-agent system coordinated via queues
Workers share the load instead of agents fighting for resources.
2.4 Multi-Agent Coordination with Dedicated Queues
Key Features Demonstrated:
-
✅ Dedicated queues per agent type
-
✅ Rate limiting for external API calls
-
✅ Parallel execution with
group() -
✅ Sequential workflows with
chain() -
✅ Result aggregation with
chord() -
✅ Automatic load balancing across workers
# multi_agent_system.pyfrom celery import Celery, group, chain, chordfrom typing import List, Dict, Anyimport logging<div></div>logger = logging.getLogger(__name__)<div></div>app = Celery('multi_agent')<div></div># Configure multiple queues for different agent typesapp.conf.task_routes = { 'agents.research.*': {'queue': 'research'}, 'agents.scraper.*': {'queue': 'scraper'}, 'agents.reviewer.*': {'queue': 'reviewer'}, 'agents.planner.*': {'queue': 'planner'}, 'agents.tool.*': {'queue': 'tools'},}<div></div># Configure rate limits per queueapp.conf.task_annotations = { 'agents.scraper.*': {'rate_limit': '10/m'}, # 10 per minute 'agents.tool.api_call': {'rate_limit': '30/m'}, # Respect API limits}<div></div># Research Agent@app.task(queue='research', bind=True)def research_agent(self, topic: str) -> Dict[str, Any]: """ Research agent: Gathers information on a topic. """ logger.info(f"Research agent processing: {topic}") try: # Simulate research (replace with actual LLM call) import time time.sleep(2) findings = { 'topic': topic, 'sources': ['source1.com', 'source2.com'], 'summary': f'Research findings for {topic}' } return { 'agent': 'research', 'status': 'success', 'data': findings } except Exception as e: logger.error(f"Research agent failed: {e}") raise<div></div># Scraper Agent@app.task(queue='scraper', bind=True, max_retries=5)def scraper_agent(self, urls: List[str]) -> Dict[str, Any]: """ Scraper agent: Extracts content from URLs. """ logger.info(f"Scraper agent processing {len(urls)} URLs") try: scraped_data = [] for url in urls: # Simulate scraping (replace with actual scraping logic) content = f"Content from {url}" scraped_data.append({'url': url, 'content': content}) return { 'agent': 'scraper', 'status': 'success', 'data': scraped_data } except Exception as exc: # Retry with exponential backoff raise self.retry(exc=exc, countdown=30 * (2 ** self.request.retries))<div></div># Reviewer Agent@app.task(queue='reviewer', bind=True)def reviewer_agent(self, content: Dict[str, Any]) -> Dict[str, Any]: """ Reviewer agent: Validates and scores content quality. """ logger.info("Reviewer agent processing content") try: # Simulate review (replace with actual LLM evaluation) quality_score = 0.85 issues = [] return { 'agent': 'reviewer', 'status': 'success', 'data': { 'quality_score': quality_score, 'issues': issues, 'approved': quality_score > 0.7 } } except Exception as e: logger.error(f"Reviewer agent failed: {e}") raise<div></div># Planner Agent@app.task(queue='planner', bind=True)def planner_agent(self, goal: str, available_agents: List[str]) -> Dict[str, Any]: """ Planner agent: Creates execution plan for multi-agent workflow. """ logger.info(f"Planner agent creating plan for: {goal}") try: # Create execution plan plan = { 'goal': goal, 'steps': [ {'agent': 'research', 'action': 'gather_info'}, {'agent': 'scraper', 'action': 'extract_data'}, {'agent': 'reviewer', 'action': 'validate'}, ] } return { 'agent': 'planner', 'status': 'success', 'data': plan } except Exception as e: logger.error(f"Planner agent failed: {e}") raise<div></div># Tool Agent@app.task(queue='tools', bind=True, rate_limit='30/m')def tool_agent_api_call(self, endpoint: str, params: Dict) -> Dict[str, Any]: """ Tool agent: Makes external API calls with rate limiting. """ logger.info(f"Tool agent calling: {endpoint}") try: # Simulate API call (replace with actual API client) import requests response = requests.get(endpoint, params=params, timeout=10) return { 'agent': 'tool', 'status': 'success', 'data': response.json() } except Exception as exc: raise self.retry(exc=exc, countdown=60)<div></div># Orchestration: Coordinating Multiple Agents@app.taskdef orchestrate_multi_agent_workflow(query: str) -> Dict[str, Any]: """ Orchestrate a complex workflow involving multiple agents. Execution pattern: 1. Planner creates the plan 2. Research and Scraper work in parallel 3. Reviewer validates the combined results """ logger.info(f"Orchestrating workflow for query: {query}") # Step 1: Create plan plan_task = planner_agent.s( goal=query, available_agents=['research', 'scraper', 'reviewer'] ) # Step 2: Execute research and scraping in parallel parallel_tasks = group( research_agent.s(topic=query), scraper_agent.s(urls=['http://example.com/1', 'http://example.com/2']) ) # Step 3: Review results after parallel execution completes review_task = reviewer_agent.s() # Chain the workflow: plan -> parallel execution -> review workflow = chain( plan_task, parallel_tasks, review_task ) # Execute asynchronously result = workflow.apply_async() return { 'workflow_id': result.id, 'status': 'submitted', 'message': 'Multi-agent workflow initiated' }<div></div># Advanced: Chord pattern for aggregation@app.taskdef aggregate_agent_results(results: List[Dict[str, Any]]) -> Dict[str, Any]: """ Aggregate results from multiple agents. Called after all parallel tasks complete. """ logger.info("Aggregating results from multiple agents") aggregated = { 'total_agents': len(results), 'successful': sum(1 for r in results if r.get('status') == 'success'), 'combined_data': [r.get('data') for r in results], 'timestamp': time.time() } return aggregated<div></div>@app.taskdef complex_multi_agent_workflow(query: str) -> str: """ Advanced workflow using chord pattern for parallel execution + aggregation. """ # Create a chord: parallel tasks + callback workflow = chord( group( research_agent.s(topic=query), scraper_agent.s(urls=['http://example.com']), tool_agent_api_call.s(endpoint='http://api.example.com', params={}) ) )(aggregate_agent_results.s()) return workflow.id# multi_agent_system.pyfrom celery import Celery, group, chain, chordfrom typing import List, Dict, Anyimport logginglogger = logging.getLogger(__name__)app = Celery('multi_agent')# Configure multiple queues for different agent typesapp.conf.task_routes = { 'agents.research.*': {'queue': 'research'}, 'agents.scraper.*': {'queue': 'scraper'}, 'agents.reviewer.*': {'queue': 'reviewer'}, 'agents.planner.*': {'queue': 'planner'}, 'agents.tool.*': {'queue': 'tools'},}# Configure rate limits per queueapp.conf.task_annotations = { 'agents.scraper.*': {'rate_limit': '10/m'}, # 10 per minute 'agents.tool.api_call': {'rate_limit': '30/m'}, # Respect API limits}# Research Agent@app.task(queue='research', bind=True)def research_agent(self, topic: str) -> Dict[str, Any]: """ Research agent: Gathers information on a topic. """ logger.info(f"Research agent processing: {topic}") try: # Simulate research (replace with actual LLM call) import time time.sleep(2) findings = { 'topic': topic, 'sources': ['source1.com', 'source2.com'], 'summary': f'Research findings for {topic}' } return { 'agent': 'research', 'status': 'success', 'data': findings } except Exception as e: logger.error(f"Research agent failed: {e}") raise# Scraper Agent@app.task(queue='scraper', bind=True, max_retries=5)def scraper_agent(self, urls: List[str]) -> Dict[str, Any]: """ Scraper agent: Extracts content from URLs. """ logger.info(f"Scraper agent processing {len(urls)} URLs") try: scraped_data = [] for url in urls: # Simulate scraping (replace with actual scraping logic) content = f"Content from {url}" scraped_data.append({'url': url, 'content': content}) return { 'agent': 'scraper', 'status': 'success', 'data': scraped_data } except Exception as exc: # Retry with exponential backoff raise self.retry(exc=exc, countdown=30 * (2 ** self.request.retries))# Reviewer Agent@app.task(queue='reviewer', bind=True)def reviewer_agent(self, content: Dict[str, Any]) -> Dict[str, Any]: """ Reviewer agent: Validates and scores content quality. """ logger.info("Reviewer agent processing content") try: # Simulate review (replace with actual LLM evaluation) quality_score = 0.85 issues = [] return { 'agent': 'reviewer', 'status': 'success', 'data': { 'quality_score': quality_score, 'issues': issues, 'approved': quality_score > 0.7 } } except Exception as e: logger.error(f"Reviewer agent failed: {e}") raise# Planner Agent@app.task(queue='planner', bind=True)def planner_agent(self, goal: str, available_agents: List[str]) -> Dict[str, Any]: """ Planner agent: Creates execution plan for multi-agent workflow. """ logger.info(f"Planner agent creating plan for: {goal}") try: # Create execution plan plan = { 'goal': goal, 'steps': [ {'agent': 'research', 'action': 'gather_info'}, {'agent': 'scraper', 'action': 'extract_data'}, {'agent': 'reviewer', 'action': 'validate'}, ] } return { 'agent': 'planner', 'status': 'success', 'data': plan } except Exception as e: logger.error(f"Planner agent failed: {e}") raise# Tool Agent@app.task(queue='tools', bind=True, rate_limit='30/m')def tool_agent_api_call(self, endpoint: str, params: Dict) -> Dict[str, Any]: """ Tool agent: Makes external API calls with rate limiting. """ logger.info(f"Tool agent calling: {endpoint}") try: # Simulate API call (replace with actual API client) import requests response = requests.get(endpoint, params=params, timeout=10) return { 'agent': 'tool', 'status': 'success', 'data': response.json() } except Exception as exc: raise self.retry(exc=exc, countdown=60)# Orchestration: Coordinating Multiple Agents@app.taskdef orchestrate_multi_agent_workflow(query: str) -> Dict[str, Any]: """ Orchestrate a complex workflow involving multiple agents. Execution pattern: 1. Planner creates the plan 2. Research and Scraper work in parallel 3. Reviewer validates the combined results """ logger.info(f"Orchestrating workflow for query: {query}") # Step 1: Create plan plan_task = planner_agent.s( goal=query, available_agents=['research', 'scraper', 'reviewer'] ) # Step 2: Execute research and scraping in parallel parallel_tasks = group( research_agent.s(topic=query), scraper_agent.s(urls=['http://example.com/1', 'http://example.com/2']) ) # Step 3: Review results after parallel execution completes review_task = reviewer_agent.s() # Chain the workflow: plan -> parallel execution -> review workflow = chain( plan_task, parallel_tasks, review_task ) # Execute asynchronously result = workflow.apply_async() return { 'workflow_id': result.id, 'status': 'submitted', 'message': 'Multi-agent workflow initiated' }# Advanced: Chord pattern for aggregation@app.taskdef aggregate_agent_results(results: List[Dict[str, Any]]) -> Dict[str, Any]: """ Aggregate results from multiple agents. Called after all parallel tasks complete. """ logger.info("Aggregating results from multiple agents") aggregated = { 'total_agents': len(results), 'successful': sum(1 for r in results if r.get('status') == 'success'), 'combined_data': [r.get('data') for r in results], 'timestamp': time.time() } return aggregated@app.taskdef complex_multi_agent_workflow(query: str) -> str: """ Advanced workflow using chord pattern for parallel execution + aggregation. """ # Create a chord: parallel tasks + callback workflow = chord( group( research_agent.s(topic=query), scraper_agent.s(urls=['http://example.com']), tool_agent_api_call.s(endpoint='http://api.example.com', params={}) ) )(aggregate_agent_results.s()) return workflow.idStarting Workers for Different Queues:
# Terminal 1: Research queue workercelery -A multi_agent_system worker -Q research -n research_worker@%h -c 2<div></div># Terminal 2: Scraper queue worker (more concurrency for I/O)celery -A multi_agent_system worker -Q scraper -n scraper_worker@%h -c 5<div></div># Terminal 3: Reviewer queue workercelery -A multi_agent_system worker -Q reviewer -n reviewer_worker@%h -c 2<div></div># Terminal 4: Planner queue workercelery -A multi_agent_system worker -Q planner -n planner_worker@%h -c 1<div></div># Terminal 5: Tool queue worker (with rate limiting)celery -A multi_agent_system worker -Q tools -n tool_worker@%h -c 3<div></div># Or start all queues with one command (development only)celery -A multi_agent_system worker -Q research,scraper,reviewer,planner,tools -c 10# Terminal 1: Research queue workercelery -A multi_agent_system worker -Q research -n research_worker@%h -c 2# Terminal 2: Scraper queue worker (more concurrency for I/O)celery -A multi_agent_system worker -Q scraper -n scraper_worker@%h -c 5# Terminal 3: Reviewer queue workercelery -A multi_agent_system worker -Q reviewer -n reviewer_worker@%h -c 2# Terminal 4: Planner queue workercelery -A multi_agent_system worker -Q planner -n planner_worker@%h -c 1# Terminal 5: Tool queue worker (with rate limiting)celery -A multi_agent_system worker -Q tools -n tool_worker@%h -c 3# Or start all queues with one command (development only)celery -A multi_agent_system worker -Q research,scraper,reviewer,planner,tools -c 102.5 Decoupling Application Logic from Agent Execution
Decoupling is essential for:
-
responsiveness
-
fault isolation
-
easier maintenance
-
retry logic
-
observability
A synchronous model ties the lifespan of the user request to the agent's operation. An async/queue architecture breaks that dependency.
Benefits:
-
The system can acknowledge user requests instantly.
-
Agent execution happens independently.
-
Failures do not crash the main application.
-
The same job can be retried, resumed, or distributed.
3. Practical Applications of Async & Queues in Agentic AI
3.1 Tool Execution Buffering
Agents make frequent tool calls:
-
DB queries
-
URL fetches
-
external API calls
-
scraping
-
long-running computations
Queues help:
-
enforce rate limits
-
batch similar requests
-
retry failures
-
distribute load across workers
3.2 Rate-Limited Tool Execution with Retry Logic
Key Features Demonstrated:
-
✅ Rate limiting with Redis
-
✅ Result caching to reduce redundant calls
-
✅ Retry logic with exponential backoff
-
✅ Batch processing for efficiency
-
✅ Priority queues for critical tasks
-
✅ Connection pooling and timeout handling
# tool_executor.pyfrom celery import Celeryfrom typing import Dict, Any, Optionalimport timeimport loggingfrom functools import wrapsfrom redis import Redisimport hashlib<div></div>logger = logging.getLogger(__name__)<div></div>app = Celery('tool_executor')<div></div># Redis for caching and rate limitingredis_client = Redis(host='localhost', port=6379, db=1, decode_responses=True)<div></div>def rate_limit(key_prefix: str, max_calls: int, time_window: int): """ Decorator for rate limiting tool calls. Args: key_prefix: Redis key prefix for this rate limit max_calls: Maximum number of calls allowed time_window: Time window in seconds """ def decorator(func): @wraps(func) def wrapper(*args, **kwargs): # Create rate limit key rate_key = f"rate_limit:{key_prefix}" # Check current count current_count = redis_client.get(rate_key) if current_count and int(current_count) >= max_calls: wait_time = redis_client.ttl(rate_key) raise Exception( f"Rate limit exceeded. Try again in {wait_time} seconds" ) # Increment counter pipe = redis_client.pipeline() pipe.incr(rate_key) pipe.expire(rate_key, time_window) pipe.execute() # Execute function return func(*args, **kwargs) return wrapper return decorator<div></div>def cache_result(ttl: int = 3600): """ Decorator to cache tool results. Args: ttl: Time to live in seconds (default 1 hour) """ def decorator(func): @wraps(func) def wrapper(*args, **kwargs): # Create cache key from function name and arguments cache_key = f"cache:{func.__name__}:{hashlib.md5(str(args).encode()).hexdigest()}" # Check cache cached_result = redis_client.get(cache_key) if cached_result: logger.info(f"Cache hit for {func.__name__}") import json return json.loads(cached_result) # Execute function result = func(*args, **kwargs) # Store in cache import json redis_client.setex(cache_key, ttl, json.dumps(result)) logger.info(f"Cached result for {func.__name__}") return result return wrapper return decorator<div></div>@app.task(bind=True, max_retries=3, default_retry_delay=60)@rate_limit(key_prefix="external_api", max_calls=30, time_window=60)@cache_result(ttl=1800) # Cache for 30 minutesdef call_external_api(self, endpoint: str, params: Dict[str, Any]) -> Dict[str, Any]: """ Call external API with rate limiting, caching, and retry logic. """ logger.info(f"Calling external API: {endpoint}") try: import requests response = requests.get( endpoint, params=params, timeout=30, headers={'User-Agent': 'AgenticAI/1.0'} ) response.raise_for_status() return { 'status': 'success', 'data': response.json(), 'cached': False } except requests.exceptions.RequestException as exc: logger.error(f"API call failed: {exc}") # Retry with exponential backoff countdown = 60 * (2 ** self.request.retries) raise self.retry(exc=exc, countdown=countdown)<div></div>@app.task(bind=True, max_retries=5)@rate_limit(key_prefix="web_scraping", max_calls=10, time_window=60)def scrape_url(self, url: str) -> Dict[str, Any]: """ Scrape URL with rate limiting and retry on failure. """ logger.info(f"Scraping: {url}") try: import requests from bs4 import BeautifulSoup response = requests.get( url, timeout=30, headers={ 'User-Agent': 'Mozilla/5.0 (compatible; AgenticBot/1.0)' } ) response.raise_for_status() soup = BeautifulSoup(response.content, 'html.parser') # Extract title and main content title = soup.find('title').text if soup.find('title') else 'No title' # Remove script and style elements for script in soup(['script', 'style']): script.decompose() text_content = soup.get_text(separator=' ', strip=True) return { 'status': 'success', 'url': url, 'title': title, 'content': text_content[:5000], # Limit content size 'length': len(text_content) } except Exception as exc: logger.error(f"Scraping failed for {url}: {exc}") # Exponential backoff: 1min, 2min, 4min, 8min, 16min countdown = 60 * (2 ** self.request.retries) raise self.retry(exc=exc, countdown=countdown, max_retries=5)<div></div>@app.task(bind=True)@rate_limit(key_prefix="database_query", max_calls=100, time_window=60)def execute_database_query(self, query: str, params: Optional[Dict] = None) -> List[Dict]: """ Execute database query with rate limiting. """ logger.info("Executing database query") try: import psycopg2 from psycopg2.extras import RealDictCursor conn = psycopg2.connect( host='localhost', database='agent_db', user='agent_user', password='secure_password', connect_timeout=10 ) with conn.cursor(cursor_factory=RealDictCursor) as cursor: cursor.execute(query, params or {}) results = cursor.fetchall() conn.close() return { 'status': 'success', 'count': len(results), 'data': results } except Exception as exc: logger.error(f"Database query failed: {exc}") raise self.retry(exc=exc, countdown=30)<div></div># Batch processing for efficiency@app.taskdef batch_api_calls(endpoints: List[str]) -> List[Dict[str, Any]]: """ Process multiple API calls efficiently using Celery groups. """ from celery import group # Create a group of parallel API call tasks job = group( call_external_api.s(endpoint=endpoint, params={}) for endpoint in endpoints ) # Execute all in parallel result = job.apply_async() # Wait for all to complete (or use result.get() in a callback) return { 'batch_id': result.id, 'total_tasks': len(endpoints), 'status': 'processing' }<div></div>@app.taskdef batch_url_scraping(urls: List[str], callback_task: Optional[str] = None) -> str: """ Scrape multiple URLs with automatic batching and rate limiting. """ from celery import chord, group # Create scraping tasks scrape_tasks = group(scrape_url.s(url) for url in urls) if callback_task: # Use chord for aggregation callback workflow = chord(scrape_tasks)(callback_task) else: # Just execute in parallel workflow = scrape_tasks.apply_async() return workflow.id# tool_executor.pyfrom celery import Celeryfrom typing import Dict, Any, Optionalimport timeimport loggingfrom functools import wrapsfrom redis import Redisimport hashliblogger = logging.getLogger(__name__)app = Celery('tool_executor')# Redis for caching and rate limitingredis_client = Redis(host='localhost', port=6379, db=1, decode_responses=True)def rate_limit(key_prefix: str, max_calls: int, time_window: int): """ Decorator for rate limiting tool calls. Args: key_prefix: Redis key prefix for this rate limit max_calls: Maximum number of calls allowed time_window: Time window in seconds """ def decorator(func): @wraps(func) def wrapper(*args, **kwargs): # Create rate limit key rate_key = f"rate_limit:{key_prefix}" # Check current count current_count = redis_client.get(rate_key) if current_count and int(current_count) >= max_calls: wait_time = redis_client.ttl(rate_key) raise Exception( f"Rate limit exceeded. Try again in {wait_time} seconds" ) # Increment counter pipe = redis_client.pipeline() pipe.incr(rate_key) pipe.expire(rate_key, time_window) pipe.execute() # Execute function return func(*args, **kwargs) return wrapper return decoratordef cache_result(ttl: int = 3600): """ Decorator to cache tool results. Args: ttl: Time to live in seconds (default 1 hour) """ def decorator(func): @wraps(func) def wrapper(*args, **kwargs): # Create cache key from function name and arguments cache_key = f"cache:{func.__name__}:{hashlib.md5(str(args).encode()).hexdigest()}" # Check cache cached_result = redis_client.get(cache_key) if cached_result: logger.info(f"Cache hit for {func.__name__}") import json return json.loads(cached_result) # Execute function result = func(*args, **kwargs) # Store in cache import json redis_client.setex(cache_key, ttl, json.dumps(result)) logger.info(f"Cached result for {func.__name__}") return result return wrapper return decorator@app.task(bind=True, max_retries=3, default_retry_delay=60)@rate_limit(key_prefix="external_api", max_calls=30, time_window=60)@cache_result(ttl=1800) # Cache for 30 minutesdef call_external_api(self, endpoint: str, params: Dict[str, Any]) -> Dict[str, Any]: """ Call external API with rate limiting, caching, and retry logic. """ logger.info(f"Calling external API: {endpoint}") try: import requests response = requests.get( endpoint, params=params, timeout=30, headers={'User-Agent': 'AgenticAI/1.0'} ) response.raise_for_status() return { 'status': 'success', 'data': response.json(), 'cached': False } except requests.exceptions.RequestException as exc: logger.error(f"API call failed: {exc}") # Retry with exponential backoff countdown = 60 * (2 ** self.request.retries) raise self.retry(exc=exc, countdown=countdown)@app.task(bind=True, max_retries=5)@rate_limit(key_prefix="web_scraping", max_calls=10, time_window=60)def scrape_url(self, url: str) -> Dict[str, Any]: """ Scrape URL with rate limiting and retry on failure. """ logger.info(f"Scraping: {url}") try: import requests from bs4 import BeautifulSoup response = requests.get( url, timeout=30, headers={ 'User-Agent': 'Mozilla/5.0 (compatible; AgenticBot/1.0)' } ) response.raise_for_status() soup = BeautifulSoup(response.content, 'html.parser') # Extract title and main content title = soup.find('title').text if soup.find('title') else 'No title' # Remove script and style elements for script in soup(['script', 'style']): script.decompose() text_content = soup.get_text(separator=' ', strip=True) return { 'status': 'success', 'url': url, 'title': title, 'content': text_content[:5000], # Limit content size 'length': len(text_content) } except Exception as exc: logger.error(f"Scraping failed for {url}: {exc}") # Exponential backoff: 1min, 2min, 4min, 8min, 16min countdown = 60 * (2 ** self.request.retries) raise self.retry(exc=exc, countdown=countdown, max_retries=5)@app.task(bind=True)@rate_limit(key_prefix="database_query", max_calls=100, time_window=60)def execute_database_query(self, query: str, params: Optional[Dict] = None) -> List[Dict]: """ Execute database query with rate limiting. """ logger.info("Executing database query") try: import psycopg2 from psycopg2.extras import RealDictCursor conn = psycopg2.connect( host='localhost', database='agent_db', user='agent_user', password='secure_password', connect_timeout=10 ) with conn.cursor(cursor_factory=RealDictCursor) as cursor: cursor.execute(query, params or {}) results = cursor.fetchall() conn.close() return { 'status': 'success', 'count': len(results), 'data': results } except Exception as exc: logger.error(f"Database query failed: {exc}") raise self.retry(exc=exc, countdown=30)# Batch processing for efficiency@app.taskdef batch_api_calls(endpoints: List[str]) -> List[Dict[str, Any]]: """ Process multiple API calls efficiently using Celery groups. """ from celery import group # Create a group of parallel API call tasks job = group( call_external_api.s(endpoint=endpoint, params={}) for endpoint in endpoints ) # Execute all in parallel result = job.apply_async() # Wait for all to complete (or use result.get() in a callback) return { 'batch_id': result.id, 'total_tasks': len(endpoints), 'status': 'processing' }@app.taskdef batch_url_scraping(urls: List[str], callback_task: Optional[str] = None) -> str: """ Scrape multiple URLs with automatic batching and rate limiting. """ from celery import chord, group # Create scraping tasks scrape_tasks = group(scrape_url.s(url) for url in urls) if callback_task: # Use chord for aggregation callback workflow = chord(scrape_tasks)(callback_task) else: # Just execute in parallel workflow = scrape_tasks.apply_async() return workflow.idConfiguration for Production:
# celeryconfig.pyfrom kombu import Queue, Exchange<div></div># Broker settingsbroker_url = 'redis://localhost:6379/0'result_backend = 'redis://localhost:6379/0'<div></div># Task execution settingstask_serializer = 'json'accept_content = ['json']result_serializer = 'json'timezone = 'UTC'enable_utc = True<div></div># Performance settingsworker_prefetch_multiplier = 4worker_max_tasks_per_child = 1000 # Restart worker after 1000 tasks<div></div># Queue configurationtask_default_queue = 'default'task_queues = ( Queue('default', Exchange('default'), routing_key='default'), Queue('high_priority', Exchange('high_priority'), routing_key='high_priority'), Queue('low_priority', Exchange('low_priority'), routing_key='low_priority'),)<div></div># Route tasks by prioritytask_routes = { 'tool_executor.call_external_api': {'queue': 'high_priority'}, 'tool_executor.scrape_url': {'queue': 'low_priority'},}<div></div># Result expirationresult_expires = 3600 # Results expire after 1 hour<div></div># Task retry settingstask_acks_late = True # Acknowledge tasks after completiontask_reject_on_worker_lost = True # Requeue if worker crashes# celeryconfig.pyfrom kombu import Queue, Exchange# Broker settingsbroker_url = 'redis://localhost:6379/0'result_backend = 'redis://localhost:6379/0'# Task execution settingstask_serializer = 'json'accept_content = ['json']result_serializer = 'json'timezone = 'UTC'enable_utc = True# Performance settingsworker_prefetch_multiplier = 4worker_max_tasks_per_child = 1000 # Restart worker after 1000 tasks# Queue configurationtask_default_queue = 'default'task_queues = ( Queue('default', Exchange('default'), routing_key='default'), Queue('high_priority', Exchange('high_priority'), routing_key='high_priority'), Queue('low_priority', Exchange('low_priority'), routing_key='low_priority'),)# Route tasks by prioritytask_routes = { 'tool_executor.call_external_api': {'queue': 'high_priority'}, 'tool_executor.scrape_url': {'queue': 'low_priority'},}# Result expirationresult_expires = 3600 # Results expire after 1 hour# Task retry settingstask_acks_late = True # Acknowledge tasks after completiontask_reject_on_worker_lost = True # Requeue if worker crashes3.3 State Management & Checkpointing
Agentic workflows are multi-step:
-
Think
-
Search
-
Analyze
-
Act
-
Reflect
-
Continue
If step 4 fails, you don’t want to restart steps 1–3.
Queues + async let you:
-
save intermediate state
-
resume partial workflows
-
persist progress
-
recover from failures gracefully

Figure 4: Diagram—Checkpoint-enabled agent workflow
3.4 Checkpoint-Enabled Agent Workflow
Key Features Demonstrated:
-
✅ Multi-stage workflow with checkpointing
-
✅ Automatic resume from failure point
-
✅ Persistent state in PostgreSQL
-
✅ Workflow history tracking
-
✅ Graceful failure handling
-
✅ No redundant work on retry
# checkpoint_workflow.pyfrom celery import Celery, Taskfrom typing import Dict, Any, List, Optionalimport jsonimport loggingfrom datetime import datetimefrom enum import Enumimport psycopg2from psycopg2.extras import Json<div></div>logger = logging.getLogger(__name__)<div></div>app = Celery('checkpoint_workflow')<div></div>class WorkflowStage(Enum): """Workflow stages for checkpointing.""" INITIALIZED = "initialized" REASONING = "reasoning" SEARCHING = "searching" ANALYZING = "analyzing" ACTING = "acting" REFLECTING = "reflecting" COMPLETED = "completed" FAILED = "failed"<div></div>class CheckpointDB: """Database handler for workflow checkpoints.""" def __init__(self): self.conn_params = { 'host': 'localhost', 'database': 'agent_workflows', 'user': 'agent_user', 'password': 'secure_password' } def save_checkpoint( self, workflow_id: str, stage: WorkflowStage, state: Dict[str, Any], metadata: Optional[Dict] = None ) -> None: """Save workflow checkpoint to database.""" try: with psycopg2.connect(**self.conn_params) as conn: with conn.cursor() as cursor: cursor.execute(""" INSERT INTO workflow_checkpoints (workflow_id, stage, state, metadata, created_at) VALUES (%s, %s, %s, %s, %s) ON CONFLICT (workflow_id, stage) DO UPDATE SET state = EXCLUDED.state, metadata = EXCLUDED.metadata, updated_at = CURRENT_TIMESTAMP """, ( workflow_id, stage.value, Json(state), Json(metadata or {}), datetime.utcnow() )) conn.commit() logger.info(f"Checkpoint saved: {workflow_id} at stage {stage.value}") except Exception as e: logger.error(f"Failed to save checkpoint: {e}") raise def load_checkpoint( self, workflow_id: str, stage: Optional[WorkflowStage] = None ) -> Optional[Dict[str, Any]]: """Load workflow checkpoint from database.""" try: with psycopg2.connect(**self.conn_params) as conn: with conn.cursor() as cursor: if stage: cursor.execute(""" SELECT stage, state, metadata, created_at FROM workflow_checkpoints WHERE workflow_id = %s AND stage = %s ORDER BY created_at DESC LIMIT 1 """, (workflow_id, stage.value)) else: # Get latest checkpoint cursor.execute(""" SELECT stage, state, metadata, created_at FROM workflow_checkpoints WHERE workflow_id = %s ORDER BY created_at DESC LIMIT 1 """, (workflow_id,)) result = cursor.fetchone() if result: return { 'stage': result[0], 'state': result[1], 'metadata': result[2], 'created_at': result[3] } return None except Exception as e: logger.error(f"Failed to load checkpoint: {e}") return None def get_workflow_history(self, workflow_id: str) -> List[Dict[str, Any]]: """Get complete history of workflow checkpoints.""" try: with psycopg2.connect(**self.conn_params) as conn: with conn.cursor() as cursor: cursor.execute(""" SELECT stage, state, metadata, created_at FROM workflow_checkpoints WHERE workflow_id = %s ORDER BY created_at ASC """, (workflow_id,)) results = cursor.fetchall() return [ { 'stage': r[0], 'state': r[1], 'metadata': r[2], 'created_at': r[3] } for r in results ] except Exception as e: logger.error(f"Failed to get workflow history: {e}") return []<div></div>checkpoint_db = CheckpointDB()<div></div>class CheckpointableTask(Task): """Base task class with checkpoint support.""" def on_failure(self, exc, task_id, args, kwargs, einfo): """Handle task failure by saving checkpoint.""" workflow_id = kwargs.get('workflow_id') if workflow_id: checkpoint_db.save_checkpoint( workflow_id=workflow_id, stage=WorkflowStage.FAILED, state={'error': str(exc)}, metadata={'task_id': task_id, 'traceback': str(einfo)} )<div></div>@app.task(base=CheckpointableTask, bind=True, max_retries=3)def execute_checkpointed_workflow( self, workflow_id: str, query: str, context: Dict[str, Any], resume_from: Optional[str] = None) -> Dict[str, Any]: """ Execute a multi-stage workflow with checkpoint support. If the workflow fails at any stage, it can resume from the last checkpoint. """ logger.info(f"Starting workflow {workflow_id}") # Check if we're resuming from a checkpoint if resume_from: checkpoint = checkpoint_db.load_checkpoint(workflow_id) if checkpoint: logger.info(f"Resuming from stage: {checkpoint['stage']}") current_stage = WorkflowStage(checkpoint['stage']) accumulated_state = checkpoint['state'] else: current_stage = WorkflowStage.INITIALIZED accumulated_state = {} else: current_stage = WorkflowStage.INITIALIZED accumulated_state = {} try: # Stage 1: Reasoning if current_stage.value in [WorkflowStage.INITIALIZED.value, WorkflowStage.REASONING.value]: logger.info("Stage 1: Reasoning") reasoning_result = perform_reasoning(query, context) accumulated_state['reasoning'] = reasoning_result checkpoint_db.save_checkpoint( workflow_id=workflow_id, stage=WorkflowStage.REASONING, state=accumulated_state, metadata={'completed_at': datetime.utcnow().isoformat()} ) current_stage = WorkflowStage.SEARCHING # Stage 2: Searching if current_stage.value == WorkflowStage.SEARCHING.value: logger.info("Stage 2: Searching") search_queries = accumulated_state['reasoning'].get('search_queries', []) search_results = perform_search(search_queries) accumulated_state['search_results'] = search_results checkpoint_db.save_checkpoint( workflow_id=workflow_id, stage=WorkflowStage.SEARCHING, state=accumulated_state, metadata={'completed_at': datetime.utcnow().isoformat()} ) current_stage = WorkflowStage.ANALYZING # Stage 3: Analyzing if current_stage.value == WorkflowStage.ANALYZING.value: logger.info("Stage 3: Analyzing") analysis = perform_analysis( accumulated_state['search_results'], accumulated_state['reasoning'] ) accumulated_state['analysis'] = analysis checkpoint_db.save_checkpoint( workflow_id=workflow_id, stage=WorkflowStage.ANALYZING, state=accumulated_state, metadata={'completed_at': datetime.utcnow().isoformat()} ) current_stage = WorkflowStage.ACTING # Stage 4: Acting if current_stage.value == WorkflowStage.ACTING.value: logger.info("Stage 4: Acting") action_result = perform_action(accumulated_state['analysis']) accumulated_state['action_result'] = action_result checkpoint_db.save_checkpoint( workflow_id=workflow_id, stage=WorkflowStage.ACTING, state=accumulated_state, metadata={'completed_at': datetime.utcnow().isoformat()} ) current_stage = WorkflowStage.REFLECTING # Stage 5: Reflecting if current_stage.value == WorkflowStage.REFLECTING.value: logger.info("Stage 5: Reflecting") reflection = perform_reflection(accumulated_state) accumulated_state['reflection'] = reflection checkpoint_db.save_checkpoint( workflow_id=workflow_id, stage=WorkflowStage.REFLECTING, state=accumulated_state, metadata={'completed_at': datetime.utcnow().isoformat()} ) current_stage = WorkflowStage.COMPLETED # Final checkpoint checkpoint_db.save_checkpoint( workflow_id=workflow_id, stage=WorkflowStage.COMPLETED, state=accumulated_state, metadata={ 'completed_at': datetime.utcnow().isoformat(), 'success': True } ) return { 'workflow_id': workflow_id, 'status': 'completed', 'result': accumulated_state } except Exception as exc: logger.error(f"Workflow failed at stage {current_stage.value}: {exc}") # Save failure checkpoint checkpoint_db.save_checkpoint( workflow_id=workflow_id, stage=current_stage, state=accumulated_state, metadata={ 'error': str(exc), 'failed_at': datetime.utcnow().isoformat() } ) # Retry from current stage raise self.retry( exc=exc, countdown=120, # Wait 2 minutes before retry kwargs={ 'workflow_id': workflow_id, 'query': query, 'context': context, 'resume_from': current_stage.value } )<div></div># Helper functions for each stagedef perform_reasoning(query: str, context: Dict[str, Any]) -> Dict[str, Any]: """Stage 1: Initial reasoning and planning.""" from openai import OpenAI client = OpenAI() response = client.chat.completions.create( model="gpt-4", messages=[ {"role": "system", "content": "You are a reasoning agent. Plan the search strategy."}, {"role": "user", "content": f"Query: {query}\nContext: {context}"} ], timeout=60 ) return { 'reasoning': response.choices[0].message.content, 'search_queries': ['query1', 'query2'], # Extract from reasoning 'approach': 'comprehensive' }<div></div>def perform_search(queries: List[str]) -> List[Dict[str, Any]]: """Stage 2: Execute search queries.""" # Simulate search (replace with actual search implementation) import time time.sleep(1) return [ {'query': q, 'results': [f'result for {q}']} for q in queries ]<div></div>def perform_analysis(search_results: List[Dict], reasoning: Dict) -> Dict[str, Any]: """Stage 3: Analyze search results.""" from openai import OpenAI client = OpenAI() response = client.chat.completions.create( model="gpt-4", messages=[ {"role": "system", "content": "Analyze the search results."}, {"role": "user", "content": f"Results: {search_results}"} ], timeout=60 ) return { 'analysis': response.choices[0].message.content, 'confidence': 0.85, 'key_findings': ['finding1', 'finding2'] }<div></div>def perform_action(analysis: Dict[str, Any]) -> Dict[str, Any]: """Stage 4: Take action based on analysis.""" # Simulate action (API call, database update, etc.) import time time.sleep(1) return { 'action_taken': 'generated_report', 'status': 'success' }<div></div>def perform_reflection(state: Dict[str, Any]) -> Dict[str, Any]: """Stage 5: Reflect on the entire process.""" return { 'quality_assessment': 'high', 'improvements': ['More sources needed'], 'success_rate': 0.9 }<div></div># API endpoint for resuming workflows@app.taskdef resume_workflow(workflow_id: str) -> Dict[str, Any]: """Resume a failed or interrupted workflow from last checkpoint.""" checkpoint = checkpoint_db.load_checkpoint(workflow_id) if not checkpoint: return { 'status': 'error', 'message': f'No checkpoint found for workflow {workflow_id}' } logger.info(f"Resuming workflow {workflow_id} from stage {checkpoint['stage']}") # Resume execution result = execute_checkpointed_workflow.delay( workflow_id=workflow_id, query=checkpoint['state'].get('query', ''), context=checkpoint['state'].get('context', {}), resume_from=checkpoint['stage'] ) return { 'status': 'resumed', 'task_id': result.id, 'resumed_from_stage': checkpoint['stage'] }# checkpoint_workflow.pyfrom celery import Celery, Taskfrom typing import Dict, Any, List, Optionalimport jsonimport loggingfrom datetime import datetimefrom enum import Enumimport psycopg2from psycopg2.extras import Jsonlogger = logging.getLogger(__name__)app = Celery('checkpoint_workflow')class WorkflowStage(Enum): """Workflow stages for checkpointing.""" INITIALIZED = "initialized" REASONING = "reasoning" SEARCHING = "searching" ANALYZING = "analyzing" ACTING = "acting" REFLECTING = "reflecting" COMPLETED = "completed" FAILED = "failed"class CheckpointDB: """Database handler for workflow checkpoints.""" def __init__(self): self.conn_params = { 'host': 'localhost', 'database': 'agent_workflows', 'user': 'agent_user', 'password': 'secure_password' } def save_checkpoint( self, workflow_id: str, stage: WorkflowStage, state: Dict[str, Any], metadata: Optional[Dict] = None ) -> None: """Save workflow checkpoint to database.""" try: with psycopg2.connect(**self.conn_params) as conn: with conn.cursor() as cursor: cursor.execute(""" INSERT INTO workflow_checkpoints (workflow_id, stage, state, metadata, created_at) VALUES (%s, %s, %s, %s, %s) ON CONFLICT (workflow_id, stage) DO UPDATE SET state = EXCLUDED.state, metadata = EXCLUDED.metadata, updated_at = CURRENT_TIMESTAMP """, ( workflow_id, stage.value, Json(state), Json(metadata or {}), datetime.utcnow() )) conn.commit() logger.info(f"Checkpoint saved: {workflow_id} at stage {stage.value}") except Exception as e: logger.error(f"Failed to save checkpoint: {e}") raise def load_checkpoint( self, workflow_id: str, stage: Optional[WorkflowStage] = None ) -> Optional[Dict[str, Any]]: """Load workflow checkpoint from database.""" try: with psycopg2.connect(**self.conn_params) as conn: with conn.cursor() as cursor: if stage: cursor.execute(""" SELECT stage, state, metadata, created_at FROM workflow_checkpoints WHERE workflow_id = %s AND stage = %s ORDER BY created_at DESC LIMIT 1 """, (workflow_id, stage.value)) else: # Get latest checkpoint cursor.execute(""" SELECT stage, state, metadata, created_at FROM workflow_checkpoints WHERE workflow_id = %s ORDER BY created_at DESC LIMIT 1 """, (workflow_id,)) result = cursor.fetchone() if result: return { 'stage': result[0], 'state': result[1], 'metadata': result[2], 'created_at': result[3] } return None except Exception as e: logger.error(f"Failed to load checkpoint: {e}") return None def get_workflow_history(self, workflow_id: str) -> List[Dict[str, Any]]: """Get complete history of workflow checkpoints.""" try: with psycopg2.connect(**self.conn_params) as conn: with conn.cursor() as cursor: cursor.execute(""" SELECT stage, state, metadata, created_at FROM workflow_checkpoints WHERE workflow_id = %s ORDER BY created_at ASC """, (workflow_id,)) results = cursor.fetchall() return [ { 'stage': r[0], 'state': r[1], 'metadata': r[2], 'created_at': r[3] } for r in results ] except Exception as e: logger.error(f"Failed to get workflow history: {e}") return []checkpoint_db = CheckpointDB()class CheckpointableTask(Task): """Base task class with checkpoint support.""" def on_failure(self, exc, task_id, args, kwargs, einfo): """Handle task failure by saving checkpoint.""" workflow_id = kwargs.get('workflow_id') if workflow_id: checkpoint_db.save_checkpoint( workflow_id=workflow_id, stage=WorkflowStage.FAILED, state={'error': str(exc)}, metadata={'task_id': task_id, 'traceback': str(einfo)} )@app.task(base=CheckpointableTask, bind=True, max_retries=3)def execute_checkpointed_workflow( self, workflow_id: str, query: str, context: Dict[str, Any], resume_from: Optional[str] = None) -> Dict[str, Any]: """ Execute a multi-stage workflow with checkpoint support. If the workflow fails at any stage, it can resume from the last checkpoint. """ logger.info(f"Starting workflow {workflow_id}") # Check if we're resuming from a checkpoint if resume_from: checkpoint = checkpoint_db.load_checkpoint(workflow_id) if checkpoint: logger.info(f"Resuming from stage: {checkpoint['stage']}") current_stage = WorkflowStage(checkpoint['stage']) accumulated_state = checkpoint['state'] else: current_stage = WorkflowStage.INITIALIZED accumulated_state = {} else: current_stage = WorkflowStage.INITIALIZED accumulated_state = {} try: # Stage 1: Reasoning if current_stage.value in [WorkflowStage.INITIALIZED.value, WorkflowStage.REASONING.value]: logger.info("Stage 1: Reasoning") reasoning_result = perform_reasoning(query, context) accumulated_state['reasoning'] = reasoning_result checkpoint_db.save_checkpoint( workflow_id=workflow_id, stage=WorkflowStage.REASONING, state=accumulated_state, metadata={'completed_at': datetime.utcnow().isoformat()} ) current_stage = WorkflowStage.SEARCHING # Stage 2: Searching if current_stage.value == WorkflowStage.SEARCHING.value: logger.info("Stage 2: Searching") search_queries = accumulated_state['reasoning'].get('search_queries', []) search_results = perform_search(search_queries) accumulated_state['search_results'] = search_results checkpoint_db.save_checkpoint( workflow_id=workflow_id, stage=WorkflowStage.SEARCHING, state=accumulated_state, metadata={'completed_at': datetime.utcnow().isoformat()} ) current_stage = WorkflowStage.ANALYZING # Stage 3: Analyzing if current_stage.value == WorkflowStage.ANALYZING.value: logger.info("Stage 3: Analyzing") analysis = perform_analysis( accumulated_state['search_results'], accumulated_state['reasoning'] ) accumulated_state['analysis'] = analysis checkpoint_db.save_checkpoint( workflow_id=workflow_id, stage=WorkflowStage.ANALYZING, state=accumulated_state, metadata={'completed_at': datetime.utcnow().isoformat()} ) current_stage = WorkflowStage.ACTING # Stage 4: Acting if current_stage.value == WorkflowStage.ACTING.value: logger.info("Stage 4: Acting") action_result = perform_action(accumulated_state['analysis']) accumulated_state['action_result'] = action_result checkpoint_db.save_checkpoint( workflow_id=workflow_id, stage=WorkflowStage.ACTING, state=accumulated_state, metadata={'completed_at': datetime.utcnow().isoformat()} ) current_stage = WorkflowStage.REFLECTING # Stage 5: Reflecting if current_stage.value == WorkflowStage.REFLECTING.value: logger.info("Stage 5: Reflecting") reflection = perform_reflection(accumulated_state) accumulated_state['reflection'] = reflection checkpoint_db.save_checkpoint( workflow_id=workflow_id, stage=WorkflowStage.REFLECTING, state=accumulated_state, metadata={'completed_at': datetime.utcnow().isoformat()} ) current_stage = WorkflowStage.COMPLETED # Final checkpoint checkpoint_db.save_checkpoint( workflow_id=workflow_id, stage=WorkflowStage.COMPLETED, state=accumulated_state, metadata={ 'completed_at': datetime.utcnow().isoformat(), 'success': True } ) return { 'workflow_id': workflow_id, 'status': 'completed', 'result': accumulated_state } except Exception as exc: logger.error(f"Workflow failed at stage {current_stage.value}: {exc}") # Save failure checkpoint checkpoint_db.save_checkpoint( workflow_id=workflow_id, stage=current_stage, state=accumulated_state, metadata={ 'error': str(exc), 'failed_at': datetime.utcnow().isoformat() } ) # Retry from current stage raise self.retry( exc=exc, countdown=120, # Wait 2 minutes before retry kwargs={ 'workflow_id': workflow_id, 'query': query, 'context': context, 'resume_from': current_stage.value } )# Helper functions for each stagedef perform_reasoning(query: str, context: Dict[str, Any]) -> Dict[str, Any]: """Stage 1: Initial reasoning and planning.""" from openai import OpenAI client = OpenAI() response = client.chat.completions.create( model="gpt-4", messages=[ {"role": "system", "content": "You are a reasoning agent. Plan the search strategy."}, {"role": "user", "content": f"Query: {query}\nContext: {context}"} ], timeout=60 ) return { 'reasoning': response.choices[0].message.content, 'search_queries': ['query1', 'query2'], # Extract from reasoning 'approach': 'comprehensive' }def perform_search(queries: List[str]) -> List[Dict[str, Any]]: """Stage 2: Execute search queries.""" # Simulate search (replace with actual search implementation) import time time.sleep(1) return [ {'query': q, 'results': [f'result for {q}']} for q in queries ]def perform_analysis(search_results: List[Dict], reasoning: Dict) -> Dict[str, Any]: """Stage 3: Analyze search results.""" from openai import OpenAI client = OpenAI() response = client.chat.completions.create( model="gpt-4", messages=[ {"role": "system", "content": "Analyze the search results."}, {"role": "user", "content": f"Results: {search_results}"} ], timeout=60 ) return { 'analysis': response.choices[0].message.content, 'confidence': 0.85, 'key_findings': ['finding1', 'finding2'] }def perform_action(analysis: Dict[str, Any]) -> Dict[str, Any]: """Stage 4: Take action based on analysis.""" # Simulate action (API call, database update, etc.) import time time.sleep(1) return { 'action_taken': 'generated_report', 'status': 'success' }def perform_reflection(state: Dict[str, Any]) -> Dict[str, Any]: """Stage 5: Reflect on the entire process.""" return { 'quality_assessment': 'high', 'improvements': ['More sources needed'], 'success_rate': 0.9 }# API endpoint for resuming workflows@app.taskdef resume_workflow(workflow_id: str) -> Dict[str, Any]: """Resume a failed or interrupted workflow from last checkpoint.""" checkpoint = checkpoint_db.load_checkpoint(workflow_id) if not checkpoint: return { 'status': 'error', 'message': f'No checkpoint found for workflow {workflow_id}' } logger.info(f"Resuming workflow {workflow_id} from stage {checkpoint['stage']}") # Resume execution result = execute_checkpointed_workflow.delay( workflow_id=workflow_id, query=checkpoint['state'].get('query', ''), context=checkpoint['state'].get('context', {}), resume_from=checkpoint['stage'] ) return { 'status': 'resumed', 'task_id': result.id, 'resumed_from_stage': checkpoint['stage'] }Database Schema for Checkpoints:
-- Create checkpoints tableCREATE TABLE IF NOT EXISTS workflow_checkpoints ( id SERIAL PRIMARY KEY, workflow_id VARCHAR(255) NOT NULL, stage VARCHAR(50) NOT NULL, state JSONB NOT NULL, metadata JSONB, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, UNIQUE(workflow_id, stage));<div></div>-- Create indexes for performanceCREATE INDEX idx_workflow_id ON workflow_checkpoints(workflow_id);CREATE INDEX idx_workflow_stage ON workflow_checkpoints(workflow_id, stage);CREATE INDEX idx_created_at ON workflow_checkpoints(created_at DESC);<div></div>-- Create function to update updated_at automaticallyCREATE OR REPLACE FUNCTION update_updated_at_column()RETURNS TRIGGER AS $$BEGIN NEW.updated_at = CURRENT_TIMESTAMP; RETURN NEW;END;$$ language 'plpgsql';<div></div>CREATE TRIGGER update_workflow_checkpoints_updated_at BEFORE UPDATE ON workflow_checkpoints FOR EACH ROW EXECUTE FUNCTION update_updated_at_column();-- Create checkpoints tableCREATE TABLE IF NOT EXISTS workflow_checkpoints ( id SERIAL PRIMARY KEY, workflow_id VARCHAR(255) NOT NULL, stage VARCHAR(50) NOT NULL, state JSONB NOT NULL, metadata JSONB, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, UNIQUE(workflow_id, stage));-- Create indexes for performanceCREATE INDEX idx_workflow_id ON workflow_checkpoints(workflow_id);CREATE INDEX idx_workflow_stage ON workflow_checkpoints(workflow_id, stage);CREATE INDEX idx_created_at ON workflow_checkpoints(created_at DESC);-- Create function to update updated_at automaticallyCREATE OR REPLACE FUNCTION update_updated_at_column()RETURNS TRIGGER AS $$BEGIN NEW.updated_at = CURRENT_TIMESTAMP; RETURN NEW;END;$$ language 'plpgsql';CREATE TRIGGER update_workflow_checkpoints_updated_at BEFORE UPDATE ON workflow_checkpoints FOR EACH ROW EXECUTE FUNCTION update_updated_at_column();4. Scaling & Load Distribution
Horizontal scaling is the backbone of robust agent systems.
With queues:
-
Add more workers = handle more tasks
-
Remove workers = lower costs
-
System auto-balances workloads
Scaling doesn’t require changing the main app.
5. Event-Driven Agent Architectures
5.1 Architecture
Many agent tasks are triggered by:
-
new data arriving
-
changes in the environment
-
user updates
-
periodic schedules (Celery Beat)
-
external webhooks
Message queues make this possible:
-
agents can subscribe to events
-
workflows run asynchronously
-
each agent wakes up only when relevant work arrives
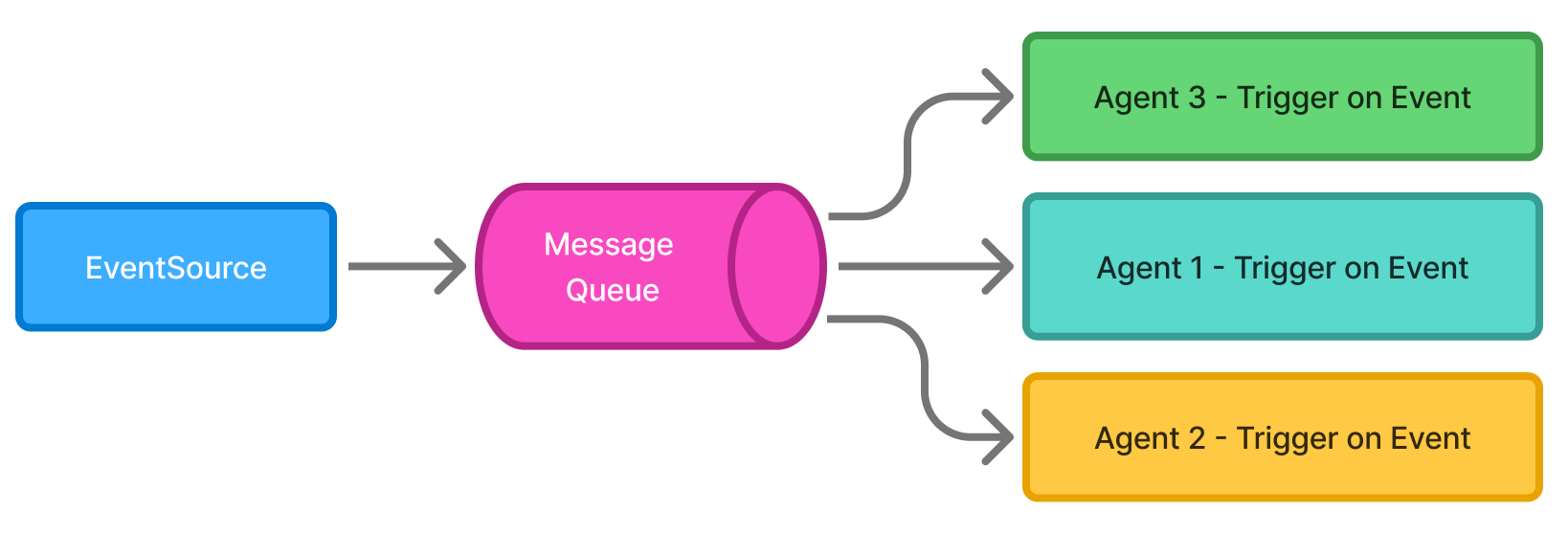
Figure 5: Diagram—Event-driven agent pipeline
5.2 Event-Driven Agent System with Webhooks
Key Features Demonstrated:
-
✅ Event-driven architecture with pub/sub
-
✅ Webhook endpoints for external integrations
-
✅ Periodic tasks with Celery Beat
-
✅ Event routing to appropriate agents
-
✅ Health monitoring and cleanup
-
✅ Signature verification for webhooks
-
✅ Redis-based event bus
# event_driven_agents.pyfrom celery import Celeryfrom celery.schedules import crontabfrom typing import Dict, Any, List, Callableimport loggingimport jsonfrom datetime import datetimefrom redis import Redisfrom fastapi import FastAPI, Request, BackgroundTasksimport hmacimport hashlib<div></div>logger = logging.getLogger(__name__)<div></div>app = Celery('event_driven_agents')api = FastAPI()<div></div># Redis for event pub/subredis_client = Redis(host='localhost', port=6379, db=2, decode_responses=True)<div></div># Configure periodic tasksapp.conf.beat_schedule = { 'monitor-data-sources-every-hour': { 'task': 'event_driven_agents.monitor_data_sources', 'schedule': crontab(minute=0), # Every hour }, 'cleanup-old-events-daily': { 'task': 'event_driven_agents.cleanup_old_events', 'schedule': crontab(hour=2, minute=0), # Daily at 2 AM }, 'health-check-every-5-minutes': { 'task': 'event_driven_agents.health_check', 'schedule': 300.0, # Every 5 minutes },}<div></div>class EventBus: """Event bus for publish/subscribe pattern.""" def __init__(self): self.redis = redis_client self.subscribers: Dict[str, List[Callable]] = {} def publish(self, event_type: str, data: Dict[str, Any]) -> None: """Publish an event to all subscribers.""" event = { 'type': event_type, 'data': data, 'timestamp': datetime.utcnow().isoformat(), 'event_id': f"{event_type}_{int(datetime.utcnow().timestamp())}" } # Store event in Redis event_key = f"events:{event_type}:{event['event_id']}" self.redis.setex(event_key, 86400, json.dumps(event)) # 24 hour TTL # Publish to channel self.redis.publish(f"channel:{event_type}", json.dumps(event)) logger.info(f"Published event: {event_type}") def subscribe(self, event_type: str, handler: Callable) -> None: """Subscribe a handler to an event type.""" if event_type not in self.subscribers: self.subscribers[event_type] = [] self.subscribers[event_type].append(handler) logger.info(f"Subscribed handler to {event_type}")<div></div>event_bus = EventBus()<div></div># Event-triggered agents@app.task(bind=True)def agent_on_new_data(self, event_data: Dict[str, Any]) -> Dict[str, Any]: """ Agent triggered when new data arrives. """ logger.info("Agent 1: Processing new data event") try: data_source = event_data.get('source') data_content = event_data.get('content') # Process the new data processed_result = { 'source': data_source, 'processed_at': datetime.utcnow().isoformat(), 'summary': f"Processed data from {data_source}", 'status': 'success' } # Publish processed event for downstream agents event_bus.publish('data_processed', processed_result) return processed_result except Exception as e: logger.error(f"Agent 1 failed: {e}") raise<div></div>@app.task(bind=True)def agent_on_environment_change(self, event_data: Dict[str, Any]) -> Dict[str, Any]: """ Agent triggered when environment changes. """ logger.info("Agent 2: Responding to environment change") try: change_type = event_data.get('change_type') impact = event_data.get('impact') # Adapt strategy based on change adaptation = { 'change_detected': change_type, 'adaptation_strategy': f"Adjusted for {change_type}", 'timestamp': datetime.utcnow().isoformat() } # Notify other systems event_bus.publish('agent_adapted', adaptation) return adaptation except Exception as e: logger.error(f"Agent 2 failed: {e}") raise<div></div>@app.task(bind=True)def agent_on_user_update(self, event_data: Dict[str, Any]) -> Dict[str, Any]: """ Agent triggered when user provides updates. """ logger.info("Agent 3: Processing user update") try: user_id = event_data.get('user_id') update_type = event_data.get('update_type') # Handle user update response = { 'user_id': user_id, 'acknowledgment': f"Processed {update_type} update", 'next_action': 'user_notified', 'timestamp': datetime.utcnow().isoformat() } return response except Exception as e: logger.error(f"Agent 3 failed: {e}") raise<div></div># Event router@app.taskdef route_event(event_type: str, event_data: Dict[str, Any]) -> List[str]: """ Route events to appropriate agent handlers. """ logger.info(f"Routing event: {event_type}") event_handlers = { 'new_data_arrived': agent_on_new_data, 'environment_changed': agent_on_environment_change, 'user_updated': agent_on_user_update, } handler = event_handlers.get(event_type) if handler: # Trigger the appropriate agent asynchronously result = handler.delay(event_data) return [result.id] else: logger.warning(f"No handler found for event: {event_type}") return []<div></div># Webhook endpoint for external events@api.post("/webhook/github")async def github_webhook(request: Request): """ Receive GitHub webhook events and trigger appropriate agents. """ # Verify webhook signature signature = request.headers.get('X-Hub-Signature-256') if not verify_github_signature(await request.body(), signature): return {'error': 'Invalid signature'}, 401 payload = await request.json() event_type = request.headers.get('X-GitHub-Event') logger.info(f"Received GitHub webhook: {event_type}") # Transform webhook to internal event event_data = { 'source': 'github', 'event_type': event_type, 'payload': payload, 'received_at': datetime.utcnow().isoformat() } # Route to appropriate agent route_event.delay('new_data_arrived', event_data) return {'status': 'accepted'}<div></div>@api.post("/webhook/slack")async def slack_webhook(request: Request): """ Receive Slack events and trigger agents. """ payload = await request.json() # Handle Slack URL verification if payload.get('type') == 'url_verification': return {'challenge': payload['challenge']} event = payload.get('event', {}) event_type = event.get('type') logger.info(f"Received Slack event: {event_type}") # Transform to internal event event_data = { 'source': 'slack', 'event_type': event_type, 'user': event.get('user'), 'text': event.get('text'), 'channel': event.get('channel') } # Trigger user update agent route_event.delay('user_updated', event_data) return {'status': 'ok'}<div></div>@api.post("/webhook/custom")async def custom_webhook(request: Request): """ Generic webhook endpoint for custom integrations. """ payload = await request.json() event_type = payload.get('event_type', 'environment_changed') event_data = payload.get('data', {}) logger.info(f"Received custom webhook: {event_type}") # Route to appropriate agent task_ids = route_event.delay(event_type, event_data) return { 'status': 'accepted', 'task_ids': task_ids }<div></div># Periodic monitoring tasks@app.taskdef monitor_data_sources(): """ Periodically check data sources for changes. Runs every hour via Celery Beat. """ logger.info("Monitoring data sources for changes") # Check various data sources data_sources = ['database', 'api', 's3_bucket'] for source in data_sources: # Simulate checking for changes has_changes = check_data_source(source) if has_changes: event_bus.publish('new_data_arrived', { 'source': source, 'content': 'New data detected', 'priority': 'high' })<div></div>@app.taskdef cleanup_old_events(): """ Clean up old events from Redis. Runs daily at 2 AM. """ logger.info("Cleaning up old events") # Get all event keys pattern = "events:*" cursor = 0 deleted_count = 0 while True: cursor, keys = redis_client.scan( cursor=cursor, match=pattern, count=100 ) for key in keys: # Check if event is older than 7 days ttl = redis_client.ttl(key) if ttl == -1: # No expiration set redis_client.delete(key) deleted_count += 1 if cursor == 0: break logger.info(f"Deleted {deleted_count} old events")<div></div>@app.taskdef health_check(): """ Perform health check on all agents. Runs every 5 minutes. """ logger.info("Performing health check") # Check Redis connection try: redis_client.ping() redis_status = 'healthy' except Exception: redis_status = 'unhealthy' # Publish health status event_bus.publish('health_check_completed', { 'redis': redis_status, 'timestamp': datetime.utcnow().isoformat() })<div></div># Utility functionsdef verify_github_signature(payload: bytes, signature: str) -> bool: """Verify GitHub webhook signature.""" secret = b'your_webhook_secret' if not signature: return False expected_signature = 'sha256=' + hmac.new( secret, payload, hashlib.sha256 ).hexdigest() return hmac.compare_digest(signature, expected_signature)<div></div>def check_data_source(source: str) -> bool: """Check if a data source has new data.""" # Implement actual checking logic import random return random.choice([True, False])# event_driven_agents.pyfrom celery import Celeryfrom celery.schedules import crontabfrom typing import Dict, Any, List, Callableimport loggingimport jsonfrom datetime import datetimefrom redis import Redisfrom fastapi import FastAPI, Request, BackgroundTasksimport hmacimport hashliblogger = logging.getLogger(__name__)app = Celery('event_driven_agents')api = FastAPI()# Redis for event pub/subredis_client = Redis(host='localhost', port=6379, db=2, decode_responses=True)# Configure periodic tasksapp.conf.beat_schedule = { 'monitor-data-sources-every-hour': { 'task': 'event_driven_agents.monitor_data_sources', 'schedule': crontab(minute=0), # Every hour }, 'cleanup-old-events-daily': { 'task': 'event_driven_agents.cleanup_old_events', 'schedule': crontab(hour=2, minute=0), # Daily at 2 AM }, 'health-check-every-5-minutes': { 'task': 'event_driven_agents.health_check', 'schedule': 300.0, # Every 5 minutes },}class EventBus: """Event bus for publish/subscribe pattern.""" def __init__(self): self.redis = redis_client self.subscribers: Dict[str, List[Callable]] = {} def publish(self, event_type: str, data: Dict[str, Any]) -> None: """Publish an event to all subscribers.""" event = { 'type': event_type, 'data': data, 'timestamp': datetime.utcnow().isoformat(), 'event_id': f"{event_type}_{int(datetime.utcnow().timestamp())}" } # Store event in Redis event_key = f"events:{event_type}:{event['event_id']}" self.redis.setex(event_key, 86400, json.dumps(event)) # 24 hour TTL # Publish to channel self.redis.publish(f"channel:{event_type}", json.dumps(event)) logger.info(f"Published event: {event_type}") def subscribe(self, event_type: str, handler: Callable) -> None: """Subscribe a handler to an event type.""" if event_type not in self.subscribers: self.subscribers[event_type] = [] self.subscribers[event_type].append(handler) logger.info(f"Subscribed handler to {event_type}")event_bus = EventBus()# Event-triggered agents@app.task(bind=True)def agent_on_new_data(self, event_data: Dict[str, Any]) -> Dict[str, Any]: """ Agent triggered when new data arrives. """ logger.info("Agent 1: Processing new data event") try: data_source = event_data.get('source') data_content = event_data.get('content') # Process the new data processed_result = { 'source': data_source, 'processed_at': datetime.utcnow().isoformat(), 'summary': f"Processed data from {data_source}", 'status': 'success' } # Publish processed event for downstream agents event_bus.publish('data_processed', processed_result) return processed_result except Exception as e: logger.error(f"Agent 1 failed: {e}") raise@app.task(bind=True)def agent_on_environment_change(self, event_data: Dict[str, Any]) -> Dict[str, Any]: """ Agent triggered when environment changes. """ logger.info("Agent 2: Responding to environment change") try: change_type = event_data.get('change_type') impact = event_data.get('impact') # Adapt strategy based on change adaptation = { 'change_detected': change_type, 'adaptation_strategy': f"Adjusted for {change_type}", 'timestamp': datetime.utcnow().isoformat() } # Notify other systems event_bus.publish('agent_adapted', adaptation) return adaptation except Exception as e: logger.error(f"Agent 2 failed: {e}") raise@app.task(bind=True)def agent_on_user_update(self, event_data: Dict[str, Any]) -> Dict[str, Any]: """ Agent triggered when user provides updates. """ logger.info("Agent 3: Processing user update") try: user_id = event_data.get('user_id') update_type = event_data.get('update_type') # Handle user update response = { 'user_id': user_id, 'acknowledgment': f"Processed {update_type} update", 'next_action': 'user_notified', 'timestamp': datetime.utcnow().isoformat() } return response except Exception as e: logger.error(f"Agent 3 failed: {e}") raise# Event router@app.taskdef route_event(event_type: str, event_data: Dict[str, Any]) -> List[str]: """ Route events to appropriate agent handlers. """ logger.info(f"Routing event: {event_type}") event_handlers = { 'new_data_arrived': agent_on_new_data, 'environment_changed': agent_on_environment_change, 'user_updated': agent_on_user_update, } handler = event_handlers.get(event_type) if handler: # Trigger the appropriate agent asynchronously result = handler.delay(event_data) return [result.id] else: logger.warning(f"No handler found for event: {event_type}") return []# Webhook endpoint for external events@api.post("/webhook/github")async def github_webhook(request: Request): """ Receive GitHub webhook events and trigger appropriate agents. """ # Verify webhook signature signature = request.headers.get('X-Hub-Signature-256') if not verify_github_signature(await request.body(), signature): return {'error': 'Invalid signature'}, 401 payload = await request.json() event_type = request.headers.get('X-GitHub-Event') logger.info(f"Received GitHub webhook: {event_type}") # Transform webhook to internal event event_data = { 'source': 'github', 'event_type': event_type, 'payload': payload, 'received_at': datetime.utcnow().isoformat() } # Route to appropriate agent route_event.delay('new_data_arrived', event_data) return {'status': 'accepted'}@api.post("/webhook/slack")async def slack_webhook(request: Request): """ Receive Slack events and trigger agents. """ payload = await request.json() # Handle Slack URL verification if payload.get('type') == 'url_verification': return {'challenge': payload['challenge']} event = payload.get('event', {}) event_type = event.get('type') logger.info(f"Received Slack event: {event_type}") # Transform to internal event event_data = { 'source': 'slack', 'event_type': event_type, 'user': event.get('user'), 'text': event.get('text'), 'channel': event.get('channel') } # Trigger user update agent route_event.delay('user_updated', event_data) return {'status': 'ok'}@api.post("/webhook/custom")async def custom_webhook(request: Request): """ Generic webhook endpoint for custom integrations. """ payload = await request.json() event_type = payload.get('event_type', 'environment_changed') event_data = payload.get('data', {}) logger.info(f"Received custom webhook: {event_type}") # Route to appropriate agent task_ids = route_event.delay(event_type, event_data) return { 'status': 'accepted', 'task_ids': task_ids }# Periodic monitoring tasks@app.taskdef monitor_data_sources(): """ Periodically check data sources for changes. Runs every hour via Celery Beat. """ logger.info("Monitoring data sources for changes") # Check various data sources data_sources = ['database', 'api', 's3_bucket'] for source in data_sources: # Simulate checking for changes has_changes = check_data_source(source) if has_changes: event_bus.publish('new_data_arrived', { 'source': source, 'content': 'New data detected', 'priority': 'high' })@app.taskdef cleanup_old_events(): """ Clean up old events from Redis. Runs daily at 2 AM. """ logger.info("Cleaning up old events") # Get all event keys pattern = "events:*" cursor = 0 deleted_count = 0 while True: cursor, keys = redis_client.scan( cursor=cursor, match=pattern, count=100 ) for key in keys: # Check if event is older than 7 days ttl = redis_client.ttl(key) if ttl == -1: # No expiration set redis_client.delete(key) deleted_count += 1 if cursor == 0: break logger.info(f"Deleted {deleted_count} old events")@app.taskdef health_check(): """ Perform health check on all agents. Runs every 5 minutes. """ logger.info("Performing health check") # Check Redis connection try: redis_client.ping() redis_status = 'healthy' except Exception: redis_status = 'unhealthy' # Publish health status event_bus.publish('health_check_completed', { 'redis': redis_status, 'timestamp': datetime.utcnow().isoformat() })# Utility functionsdef verify_github_signature(payload: bytes, signature: str) -> bool: """Verify GitHub webhook signature.""" secret = b'your_webhook_secret' if not signature: return False expected_signature = 'sha256=' + hmac.new( secret, payload, hashlib.sha256 ).hexdigest() return hmac.compare_digest(signature, expected_signature)def check_data_source(source: str) -> bool: """Check if a data source has new data.""" # Implement actual checking logic import random return random.choice([True, False])Starting the Event-Driven System:
# Terminal 1: Start Celery worker for event processingcelery -A event_driven_agents worker --loglevel=info -Q default -c 4<div></div># Terminal 2: Start Celery Beat for periodic taskscelery -A event_driven_agents beat --loglevel=info<div></div># Terminal 3: Start FastAPI webhook serveruvicorn event_driven_agents:api --host 0.0.0.0 --port 8000 --reload<div></div># Terminal 4: Monitor with Flowercelery -A event_driven_agents flower --port=5555# Terminal 1: Start Celery worker for event processingcelery -A event_driven_agents worker --loglevel=info -Q default -c 4# Terminal 2: Start Celery Beat for periodic taskscelery -A event_driven_agents beat --loglevel=info# Terminal 3: Start FastAPI webhook serveruvicorn event_driven_agents:api --host 0.0.0.0 --port 8000 --reload# Terminal 4: Monitor with Flowercelery -A event_driven_agents flower --port=5555Testing the Event System:
# test_events.pyimport requestsimport json<div></div># Test custom webhookresponse = requests.post( 'http://localhost:8000/webhook/custom', json={ 'event_type': 'environment_changed', 'data': { 'change_type': 'api_rate_limit_increased', 'impact': 'high', 'details': 'Rate limit increased to 1000/hour' } })<div></div>print(f"Response: {response.json()}")<div></div># Test direct event publishingfrom event_driven_agents import event_bus<div></div>event_bus.publish('new_data_arrived', { 'source': 'manual_trigger', 'content': 'Test data', 'priority': 'low'})# test_events.pyimport requestsimport json# Test custom webhookresponse = requests.post( 'http://localhost:8000/webhook/custom', json={ 'event_type': 'environment_changed', 'data': { 'change_type': 'api_rate_limit_increased', 'impact': 'high', 'details': 'Rate limit increased to 1000/hour' } })print(f"Response: {response.json()}")# Test direct event publishingfrom event_driven_agents import event_busevent_bus.publish('new_data_arrived', { 'source': 'manual_trigger', 'content': 'Test data', 'priority': 'low'})6. Production Deployment with Docker
docker-compose.yml
# docker-compose.ymlversion: '3.8'<div></div>services: # Redis - Message broker and cache redis: image: redis:7-alpine ports: - "6379:6379" volumes: - redis_data:/data command: redis-server --appendonly yes healthcheck: test: ["CMD", "redis-cli", "ping"] interval: 10s timeout: 3s retries: 3<div></div> # PostgreSQL - State management postgres: image: postgres:15-alpine environment: POSTGRES_DB: agent_workflows POSTGRES_USER: agent_user POSTGRES_PASSWORD: secure_password ports: - "5432:5432" volumes: - postgres_data:/var/lib/postgresql/data - ./init_db.sql:/docker-entrypoint-initdb.d/init.sql healthcheck: test: ["CMD-SHELL", "pg_isready -U agent_user"] interval: 10s timeout: 5s retries: 5<div></div> # Celery Worker - Agent execution celery_worker: build: . command: celery -A multi_agent_system worker --loglevel=info -c 4 depends_on: - redis - postgres environment: CELERY_BROKER_URL: redis://redis:6379/0 CELERY_RESULT_BACKEND: redis://redis:6379/0 DATABASE_URL: postgresql://agent_user:secure_password@postgres:5432/agent_workflows OPENAI_API_KEY: ${OPENAI_API_KEY} volumes: - ./:/app restart: unless-stopped<div></div> # Celery Beat - Periodic tasks celery_beat: build: . command: celery -A event_driven_agents beat --loglevel=info depends_on: - redis - postgres environment: CELERY_BROKER_URL: redis://redis:6379/0 CELERY_RESULT_BACKEND: redis://redis:6379/0 volumes: - ./:/app restart: unless-stopped<div></div> # Flower - Monitoring dashboard flower: build: . command: celery -A multi_agent_system flower --port=5555 ports: - "5555:5555" depends_on: - redis - celery_worker environment: CELERY_BROKER_URL: redis://redis:6379/0 CELERY_RESULT_BACKEND: redis://redis:6379/0 restart: unless-stopped<div></div> # FastAPI - Web server for webhooks api: build: . command: uvicorn event_driven_agents:api --host 0.0.0.0 --port 8000 ports: - "8000:8000" depends_on: - redis - postgres environment: CELERY_BROKER_URL: redis://redis:6379/0 DATABASE_URL: postgresql://agent_user:secure_password@postgres:5432/agent_workflows volumes: - ./:/app restart: unless-stopped<div></div>volumes: redis_data: postgres_data:# docker-compose.ymlversion: '3.8'services: # Redis - Message broker and cache redis: image: redis:7-alpine ports: - "6379:6379" volumes: - redis_data:/data command: redis-server --appendonly yes healthcheck: test: ["CMD", "redis-cli", "ping"] interval: 10s timeout: 3s retries: 3 # PostgreSQL - State management postgres: image: postgres:15-alpine environment: POSTGRES_DB: agent_workflows POSTGRES_USER: agent_user POSTGRES_PASSWORD: secure_password ports: - "5432:5432" volumes: - postgres_data:/var/lib/postgresql/data - ./init_db.sql:/docker-entrypoint-initdb.d/init.sql healthcheck: test: ["CMD-SHELL", "pg_isready -U agent_user"] interval: 10s timeout: 5s retries: 5 # Celery Worker - Agent execution celery_worker: build: . command: celery -A multi_agent_system worker --loglevel=info -c 4 depends_on: - redis - postgres environment: CELERY_BROKER_URL: redis://redis:6379/0 CELERY_RESULT_BACKEND: redis://redis:6379/0 DATABASE_URL: postgresql://agent_user:secure_password@postgres:5432/agent_workflows OPENAI_API_KEY: ${OPENAI_API_KEY} volumes: - ./:/app restart: unless-stopped # Celery Beat - Periodic tasks celery_beat: build: . command: celery -A event_driven_agents beat --loglevel=info depends_on: - redis - postgres environment: CELERY_BROKER_URL: redis://redis:6379/0 CELERY_RESULT_BACKEND: redis://redis:6379/0 volumes: - ./:/app restart: unless-stopped # Flower - Monitoring dashboard flower: build: . command: celery -A multi_agent_system flower --port=5555 ports: - "5555:5555" depends_on: - redis - celery_worker environment: CELERY_BROKER_URL: redis://redis:6379/0 CELERY_RESULT_BACKEND: redis://redis:6379/0 restart: unless-stopped # FastAPI - Web server for webhooks api: build: . command: uvicorn event_driven_agents:api --host 0.0.0.0 --port 8000 ports: - "8000:8000" depends_on: - redis - postgres environment: CELERY_BROKER_URL: redis://redis:6379/0 DATABASE_URL: postgresql://agent_user:secure_password@postgres:5432/agent_workflows volumes: - ./:/app restart: unless-stoppedvolumes: redis_data: postgres_data:Dockerfile
# DockerfileFROM python:3.11-slim<div></div>WORKDIR /app<div></div># Install system dependenciesRUN apt-get update && apt-get install -y \ gcc \ postgresql-client \ && rm -rf /var/lib/apt/lists/*<div></div># Install Python dependenciesCOPY requirements.txt .RUN pip install --no-cache-dir -r requirements.txt<div></div># Copy application codeCOPY . .<div></div># Run as non-root userRUN useradd -m -u 1000 celeryuser && chown -R celeryuser:celeryuser /appUSER celeryuser<div></div>CMD ["celery", "-A", "multi_agent_system", "worker", "--loglevel=info"]# DockerfileFROM python:3.11-slimWORKDIR /app# Install system dependenciesRUN apt-get update && apt-get install -y \ gcc \ postgresql-client \ && rm -rf /var/lib/apt/lists/*# Install Python dependenciesCOPY requirements.txt .RUN pip install --no-cache-dir -r requirements.txt# Copy application codeCOPY . .# Run as non-root userRUN useradd -m -u 1000 celeryuser && chown -R celeryuser:celeryuser /appUSER celeryuserCMD ["celery", "-A", "multi_agent_system", "worker", "--loglevel=info"]requirements.txt
# requirements.txtcelery[redis]==5.3.4redis==5.0.1psycopg2-binary==2.9.9openai==1.3.0fastapi==0.104.1uvicorn[standard]==0.24.0flower==2.0.1requests==2.31.0beautifulsoup4==4.12.2pydantic==2.5.0python-multipart==0.0.6# requirements.txtcelery[redis]==5.3.4redis==5.0.1psycopg2-binary==2.9.9openai==1.3.0fastapi==0.104.1uvicorn[standard]==0.24.0flower==2.0.1requests==2.31.0beautifulsoup4==4.12.2pydantic==2.5.0python-multipart==0.0.6Start the entire system:
# Build and start all servicesdocker-compose up --build -d<div></div># View logsdocker-compose logs -f celery_worker<div></div># Scale workersdocker-compose up -d --scale celery_worker=5<div></div># Stop all servicesdocker-compose down# Build and start all servicesdocker-compose up --build -d# View logsdocker-compose logs -f celery_worker# Scale workersdocker-compose up -d --scale celery_worker=5# Stop all servicesdocker-compose down7. Frequently Asked Questions
7.1 What is asynchronous processing in agentic AI?
Asynchronous processing in agentic AI allows autonomous agents to execute tasks without blocking the main application thread. Instead of waiting for long-running operations like LLM calls, tool invocations, or web scraping to complete, the system places these tasks in a queue and immediately returns control to the user. Worker processes handle the actual execution independently, enabling the system to remain responsive while agents perform complex, time-consuming operations in the background.
7.2 Why do AI agents need message queues?
AI agents need message queues to handle three critical challenges: unpredictable timing (agent operations can take seconds to minutes), variable workloads (multiple agents may need resources simultaneously), and coordination complexity (agents must communicate without conflicts). Message queues act as buffers that throttle requests, prioritize tasks, enable retry logic, and distribute workload across multiple workers, preventing system overload and resource contention.
7.3 What's the difference between synchronous and asynchronous agent execution?
In synchronous execution, the system waits for each agent operation to complete before proceeding, causing user requests to block, threads to get stuck, and timeouts to occur frequently. In asynchronous execution, the system immediately acknowledges requests, places tasks in a queue with a tracking ID, and allows worker processes to handle operations independently. This decoupling means failures don't crash the main application, tasks can be retried automatically, and the system scales by simply adding more workers.
7.4 Which message broker is best for agentic AI systems?
The choice depends on your requirements:
-
Redis - Best for simple, high-speed queuing with low latency; ideal for prototypes and moderate-scale systems
-
RabbitMQ - Excellent for complex routing, reliable delivery guarantees, and fine-grained control; suited for enterprise production systems
-
Apache Kafka - Optimal for event streaming, high-throughput scenarios, and when you need message replay capabilities
-
AWS SQS - Best for cloud-native applications requiring minimal infrastructure management
Most production agentic AI systems start with Redis for simplicity and scale to RabbitMQ or Kafka as requirements grow.
7.5 How do queues enable multi-agent coordination?
Queues enable multi-agent coordination by providing a centralized task distribution mechanism. Instead of agents competing directly for resources like API rate limits, database connections, or external services, they submit work to specialized queues. Workers pull tasks at a controlled rate, preventing overwhelming downstream services. Different agent types (research, scraper, reviewer, planner) can have dedicated queues with different priorities, and the system automatically load-balances work across available workers.
7.6 What happens if an agent task fails in a queue-based system?
Queue-based systems provide robust failure handling through several mechanisms:
-
Automatic retries - Failed tasks return to the queue with exponential backoff
-
Dead letter queues - Tasks failing repeatedly move to a separate queue for investigation
-
State persistence - Intermediate results are checkpointed, so work doesn't need to restart from scratch
-
Circuit breakers - Repeated failures can temporarily disable problematic agents
-
Monitoring - Failed tasks generate alerts for investigation
This graceful degradation ensures one failing agent doesn't bring down the entire system.
7.7 How does async processing improve agent scalability?
Async processing enables horizontal scalability - the easiest and most cost-effective scaling strategy. When demand increases, you simply add more worker processes without modifying application code. The queue automatically distributes work across all available workers. When demand decreases, you reduce worker count to save costs. This elastic scaling is impossible with synchronous architectures, where each additional concurrent user requires dedicated thread resources that remain blocked during long operations.
7.8 Can I use async processing for real-time agent interactions?
Yes, but with careful architecture. For truly real-time interactions (sub-second responses), use async processing for heavy operations while keeping lightweight responses synchronous. Implement streaming responses where the agent immediately returns a connection, then streams results as they become available. Use WebSockets or Server-Sent Events (SSE) to push updates to users. Reserve synchronous execution only for simple queries that complete in milliseconds, and use queues for everything else.
7.9 What tools do I need to implement async agent processing?
A production-ready async agent system typically requires:
Task Queue Framework:
-
Celery (Python) - Most popular, mature ecosystem
-
RQ (Redis Queue) - Simpler alternative for smaller projects
-
Dramatiq - Modern alternative with better defaults
Message Broker:
-
Redis - Fast, simple setup
-
RabbitMQ - Enterprise-grade reliability
-
AWS SQS - Cloud-native managed service
State Management:
-
PostgreSQL - Structured data and ACID guarantees
-
MongoDB - Flexible schema for agent states
-
Redis - Fast intermediate state storage
Monitoring:
-
Flower - Celery monitoring dashboard
-
Prometheus + Grafana - Metrics and alerting
-
CloudWatch - AWS-native monitoring
7.10 How do I handle long-running agent workflows with checkpoints?
Implement checkpointing by breaking workflows into discrete steps and persisting state after each step:
-
Define stages - Break workflows into logical units (Think → Search → Analyze → Act → Reflect)
-
Save intermediate state - Store results and context after each stage completion
-
Use unique task IDs - Track workflow progress with persistent identifiers
-
Implement resume logic - On failure, check last completed stage and continue from there
-
Set timeouts per stage - Prevent individual steps from hanging indefinitely
-
Store in durable storage - Use databases, not just in-memory caches
This approach means a failure at step 4 doesn't require restarting steps 1-3, saving time and API costs.
8. Conclusion: Async + Queues = Agentic AI Superpower
Asynchronous processing and message queues are not optional in agentic systems—they are foundational.
They enable:
✔ Non-blocking agent tasks
✔ Multi-agent concurrency
✔ Reliable tool execution
✔ State persistence
✔ Event-driven autonomy
✔ Horizontal scaling
✔ Decoupled architecture
In short:
Without async and queues, autonomous AI would collapse under its own complexity. They make agentic systems resilient, scalable, and production-grade.
Related Articles
- Agent Building Blocks: Build Production-Ready AI Agents with LangChain | Complete Developer Guide
- Building Agents That Remember: State Management in Multi-Agent AI Systems
- Building Production-Ready Agentic AI: The Infrastructure Nobody Talks About
- Building Production-Ready AI Agents with LangGraph: A Developer's Guide to Deterministic Workflows
Follow for more technical deep dives on AI/ML systems, production engineering, and building real-world applications: