In modern AI pipelines, provenance — the lineage of datasets, models, and inferences — is becoming as important as accuracy metrics. Regulators, auditors, and even downstream consumers increasingly demand answers to questions like:
-
Which dataset was this model trained on?
-
What code commit produced this artifact?
-
How do we know logs weren’t tampered with after training?
To learn more about provenance in AI, read my previous article: Provenance in AI: Why It Matters for AI Engineers - Part 1
To answer the above-raised questions, let’s walk through a Python-based provenance tracker that logs lineage events, cryptographically signs them, and maintains schema versioning for forward compatibility.
1. The Provenance Tracker: Key Features
The ProvenanceTracker implements three important ideas:
-
Multiple dataset support
-
Models often train on more than one dataset (train + validation + test).
-
This tracker keeps a list of dataset hashes (
dataset_hashes) and auto-links them to model logs.
-
-
Signed JSONL envelopes
-
Each log entry is wrapped in an envelope:
{ "schema_version": "1.1", "signed_data": "{…}", "signature": "" } -
signed_datais serialized with stable JSON (sort_keys=True). -
A digital signature (RSA + PSS padding + SHA-256) is generated using a private key.
-
-
Schema versioning
schema_version = "1.1"is embedded in every record.
2. The Provenance Tracker: Source Code
Before we get to the provenance tracker code, let's see a companion script generate_keys.py that creates the RSA keypair (private_key.pem, public_key.pem). This is used by the ProvenanceTracker.py to sign the JSONL logs.
# generate_keys.pyfrom cryptography.hazmat.primitives.asymmetric import rsafrom cryptography.hazmat.primitives import serialization# Generate RSA private key (2048 bits)private_key = rsa.generate_private_key( public_exponent=65537, key_size=2048,)# Save private key (PEM)with open("private_key.pem", "wb") as f: f.write( private_key.private_bytes( encoding=serialization.Encoding.PEM, format=serialization.PrivateFormat.PKCS8, encryption_algorithm=serialization.NoEncryption(), ) )# Save public key (PEM)public_key = private_key.public_key()with open("public_key.pem", "wb") as f: f.write( public_key.public_bytes( encoding=serialization.Encoding.PEM, format=serialization.PublicFormat.SubjectPublicKeyInfo, ) )print("✅ RSA keypair generated: private_key.pem & public_key.pem")Run once to create your keypair:
python generate_keys.py
Here’s a secure ProvenanceTracker (schema version 1.1) that:
-
Supports multiple datasets
-
Includes schema version
-
Signs JSONL using RSA private key
# ProvenanceTracker.pyimport hashlibimport jsonimport osimport platformimport socketimport subprocessimport base64from datetime import datetimefrom typing import Any, Dict, Listfrom cryptography.hazmat.primitives import hashes, serializationfrom cryptography.hazmat.primitives.asymmetric import paddingclass ProvenanceTracker: SCHEMA_VERSION = "1.1" def __init__(self, storage_path: str = "provenance_logs.jsonl", private_key_path: str = "private_key.pem"): self.storage_path = storage_path self._dataset_hashes: List[str] = [] # track datasets used self.private_key = self._load_private_key(private_key_path) def _load_private_key(self, path: str): with open(path, "rb") as f: return serialization.load_pem_private_key(f.read(), password=None) def _get_git_commit(self) -> str: try: return subprocess.check_output( ["git", "rev-parse", "HEAD"], stderr=subprocess.DEVNULL ).decode("utf-8").strip() except Exception: return "N/A" def _hash_file(self, file_path: str) -> str: h = hashlib.sha256() with open(file_path, "rb") as f: while chunk := f.read(8192): h.update(chunk) return h.hexdigest() def _sign(self, payload: str) -> str: signature = self.private_key.sign( payload.encode("utf-8"), padding.PSS( mgf=padding.MGF1(hashes.SHA256()), salt_length=padding.PSS.MAX_LENGTH, ), hashes.SHA256(), ) return base64.b64encode(signature).decode("utf-8") def _log(self, record: Dict[str, Any]): record["timestamp"] = datetime.utcnow().isoformat() record["schema_version"] = self.SCHEMA_VERSION # Serialize signed_data separately (stable JSON encoding) signed_data = json.dumps(record, sort_keys=True) signature = self._sign(signed_data) envelope = { "schema_version": self.SCHEMA_VERSION, "signed_data": signed_data, "signature": signature, } with open(self.storage_path, "a") as f: f.write(json.dumps(envelope) + "\n") def log_dataset(self, dataset_path: str, description: str = ""): dataset_hash = self._hash_file(dataset_path) self._dataset_hashes.append(dataset_hash) record = { "type": "dataset", "path": dataset_path, "hash": dataset_hash, "description": description, } self._log(record) return dataset_hash def log_model(self, model_name: str, hyperparams: Dict[str, Any]): record = { "type": "model", "model_name": model_name, "hyperparameters": hyperparams, "git_commit": self._get_git_commit(), "environment": { "python_version": platform.python_version(), "platform": platform.system(), "hostname": socket.gethostname(), }, "dataset_hashes": self._dataset_hashes, # link all datasets } self._log(record) def log_inference(self, model_name: str, input_data: Any, output_data: Any): record = { "type": "inference", "id": f"inf-{hashlib.sha1(json.dumps(input_data).encode()).hexdigest()[:12]}", # deterministic ID "model_name": model_name, "input": input_data, "output": output_data, } self._log(record)if __name__ == "__main__": tracker = ProvenanceTracker() # 1. Log datasets ds1 = tracker.log_dataset("data/training.csv", "Customer churn dataset") ds2 = tracker.log_dataset("data/validation.csv", "Validation set") # 2. Log model (linked to all datasets seen so far) tracker.log_model("churn-predictor-v2", { "algorithm": "XGBoost", "n_estimators": 200, "max_depth": 12, }) # 3. Log inference tracker.log_inference( "churn-predictor-v2", {"customer_id": 54321, "features": [0.4, 1.7, 0.2]}, {"churn_risk": 0.42} ) print("✅ Signed provenance logs recorded in provenance_logs.jsonl")3. Under the Hood
3.1 Datasets
Datasets are logged with a SHA-256 file hash, ensuring that even if file names change, the integrity check remains stable.
ds1 = tracker.log_dataset("data/training.csv", "Customer churn dataset")ds2 = tracker.log_dataset("data/validation.csv", "Validation set")Resulting record (inside signed_data):
{ "type": "dataset", "path": "data/training.csv", "hash": "a41be7b96f...", "description": "Customer churn dataset", "timestamp": "2025-08-28T10:12:34.123456", "schema_version": "1.1"}3.2 Models
When logging a model, the tracker attaches:
-
Model metadata (name, hyperparameters)
-
Git commit hash (if available)
-
Runtime environment (Python version, OS, hostname)
-
All dataset hashes seen so far
tracker.log_model("churn-predictor-v2", { "algorithm": "XGBoost", "n_estimators": 200, "max_depth": 12,})This creates a strong lineage link:
Dataset(s) → Model
3.3 Inferences
Every inference is logged with a deterministic ID, computed as a SHA-1 hash of the input payload. This ensures repeat queries generate the same inference ID (helpful for deduplication).
tracker.log_inference( "churn-predictor-v2", {"customer_id": 54321, "features": [0.4, 1.7, 0.2]}, {"churn_risk": 0.42})Graphically:
Model → Inference
4. Signed Envelopes for Tamper-Proofing
Each record is not stored raw but wrapped in a signed envelope:
{ "schema_version": "1.1", "signed_data": "{\"description\": \"Validation set\", \"hash\": \"c62...\"}", "signature": "MEUCIQDgtd...xyz..."}To verify:
-
Load the public key.
-
Verify the
signatureagainst the serializedsigned_data. -
If modified, verification fails → tampering detected.
This is exactly the mechanism PKI systems and blockchain protocols use for immutability.
5. Example End-to-End Run
When running ProvenanceTracker.py:
$ python ProvenanceTracker.py✅ Signed provenance logs recorded in provenance_logs.jsonlThe log file (provenance_logs.jsonl) will contain three signed envelopes — one each for datasets, the model, and an inference.
Following is provenance_logs.jsonl after run:
{"schema_version": "1.1", "signed_data": "{\"description\": \"Customer churn dataset\", \"hash\": \"a41be7b96fb85110521bf03d1530879e9ca94b9f5de19866757f6d184300fff7\", \"path\": \"data/training.csv\", \"schema_version\": \"1.1\", \"timestamp\": \"2025-08-28T01:06:31.062695\", \"type\": \"dataset\"}", "signature": "MnCRJ+Acg0F1UledjnMwQMp24wAIPmLPaZonI7hvdFvdi7d8CaZDOIamNq0KnRgcZgttJnI1L675tqT1O1M5N2FRNuy/Wj6elzpyM9w56Kd2mBcQLFumhVHiGZHtwKj2wQtXND0SCqWo5jxQPLPl0dSFClA+FKzpxfazwMtrHAE7aoUmyt2cv1Wiv9uZxsE+Il226J91rBk03lpLcArqqxTtfstkayOK5AON9ETXs65ERf26oURngR/0HS9jnO0IH1DxZOcHcfWZMrLwGqdjRF1sSDYcH70XV61yeYzSeIb8KDODttuxxfzsIlb0897tv/ZZ/X4tv/FFICei7LeAuw=="}{"schema_version": "1.1", "signed_data": "{\"description\": \"Validation set\", \"hash\": \"330af932f2dc1cae917f3bd0fb29395c4021319dd906189b7dc257d0ad58a617\", \"path\": \"data/validation.csv\", \"schema_version\": \"1.1\", \"timestamp\": \"2025-08-28T01:06:31.070827\", \"type\": \"dataset\"}", "signature": "pu8IvzPriN6eP9HTQGlIog8nfXV0FOEw818aw6uJS8oPKiQPjN3odzbP9zaeB+ZW4Nu9bBL5fm1btiiOSm9ziWUJWUzFRoHwlYTv2rgp/IXR0oWfTpXsdVeBj7NYVjUywLPofTeEE1C4J7XzZmusuCU9ZiKJzXU442E6Gsrj6tjRJxZoylONuekxegdTot4LwIcmCRtgigi1t3rQYBGdknmTFdW/I2h1Gguh+Shc/WG/jVuMq10vFNNM8iUJJAxAEktbpfhGw0of6lrZu9yn4wAmxvq0DFICKMEJlsyvEZ/mDaPkR4D55xuJh+dLlFbzNZvyw0woMII0hbIarNmG+w=="}{"schema_version": "1.1", "signed_data": "{\"dataset_hashes\": [\"a41be7b96fb85110521bf03d1530879e9ca94b9f5de19866757f6d184300fff7\", \"330af932f2dc1cae917f3bd0fb29395c4021319dd906189b7dc257d0ad58a617\"], \"environment\": {\"hostname\": \"GlamorPC\", \"platform\": \"Windows\", \"python_version\": \"3.10.11\"}, \"git_commit\": \"N/A\", \"hyperparameters\": {\"algorithm\": \"XGBoost\", \"max_depth\": 12, \"n_estimators\": 200}, \"model_name\": \"churn-predictor-v2\", \"schema_version\": \"1.1\", \"timestamp\": \"2025-08-28T01:06:31.117627\", \"type\": \"model\"}", "signature": "tq/y6Blz04u2iYZh5OqfyZChADA+osNIzwb9Z2g++AZjFu2hkywazf19rbTMsdx9J5s4BDz6rglfcFczRW/TXMECD3k91ZmAds/e0I+Xw42xeTnr7+jHKq5kPdV6Pan8yFVd9ikGso93ZDatX72rx+orIg41BggFN7ifYlKNnGD87zCypahI7Eev0frnD6w8GybmPcBMnCVLYlIo2nWpLgJELkVpwwagQ9rKA+WOlBbLe41ZizooSL/hhGJOXTuwYrkJpBZ69TIwCzihINr+joZBqYrPF+0E+CFohdc03b0SFv1OuNTo7dyqL9qpWdCMSi1iK0LfCukCO41Bvr2yHA=="}{"schema_version": "1.1", "signed_data": "{\"id\": \"inf-0276b2064ad0\", \"input\": {\"customer_id\": 54321, \"features\": [0.4, 1.7, 0.2]}, \"model_name\": \"churn-predictor-v2\", \"output\": {\"churn_risk\": 0.42}, \"schema_version\": \"1.1\", \"timestamp\": \"2025-08-28T01:06:31.118634\", \"type\": \"inference\"}", "signature": "Lf9r1vcXOaCxSc11UKNvuDjx7FophWXBxAobYlixIJgNIk2toFtEdjB2zzJtQI5cYEAImhNHB8hdssKUv3Dths0SpKeMQjpb0x0aKvXolnNsJMnEnGP443IRfMTpkcHpRjCVjIfEvP8EtAh58z4yHE77cy2IlSUFu3exwSEcRFVqBXvIKlojQTEneERUwEDZjfniluomSCLXiVFYMIB+LefPHGkChCVVulmyFJ9ITquD4Wymp2/c2/knopqXSP00EFON4SBOD9/RyQAXAl5UxP0s6faD7NeZxAdJWh3CY31+5V3Vv8b9y/jroAvxWjbpuCZT20gkHemArawDae3s0w=="}The following is the standalone verification code validate_logs.py:
#!/usr/bin/env python3"""Usage: python validate_logs.py provenance_logs.jsonl public_key.pem"""import jsonimport base64import sysfrom cryptography.hazmat.primitives import hashesfrom cryptography.hazmat.primitives.asymmetric import paddingfrom cryptography.hazmat.primitives.serialization import load_pem_public_keyEXPECTED_SCHEMA = "1.1"def load_public_key(path: str): with open(path, "rb") as f: return load_pem_public_key(f.read())def verify_signature(public_key, signed_data: str, signature_b64: str) -> bool: try: signature = base64.b64decode(signature_b64) public_key.verify( signature, signed_data.encode("utf-8"), padding.PSS( mgf=padding.MGF1(hashes.SHA256()), salt_length=padding.PSS.MAX_LENGTH, ), hashes.SHA256(), ) return True except Exception: return Falsedef validate_file(jsonl_path: str, pubkey_path: str): public_key = load_public_key(pubkey_path) valid_count = 0 failed_count = 0 schema_mismatch = 0 with open(jsonl_path, "r") as f: for line_no, line in enumerate(f, start=1): try: envelope = json.loads(line.strip()) except json.JSONDecodeError: print(f"❌ Line {line_no}: invalid JSON") failed_count += 1 continue schema = envelope.get("schema_version") signed_data = envelope.get("signed_data") signature = envelope.get("signature") if schema != EXPECTED_SCHEMA: print(f"⚠️ Line {line_no}: schema version mismatch ({schema})") schema_mismatch += 1 continue if not signed_data or not signature: print(f"❌ Line {line_no}: missing signed_data/signature") failed_count += 1 continue if verify_signature(public_key, signed_data, signature): valid_count += 1 else: print(f"❌ Line {line_no}: signature verification failed") failed_count += 1 print("\n--- Validation Report ---") print(f"✅ Valid entries : {valid_count}") print(f"❌ Signature failures : {failed_count}") print(f"⚠️ Schema mismatches : {schema_mismatch}") print(f"📄 Total lines : {valid_count + failed_count + schema_mismatch}")if __name__ == "__main__": if len(sys.argv) != 3: print("Usage: python validate_logs.py provenance_logs.jsonl public_key.pem") sys.exit(1) jsonl_file = sys.argv[1] pubkey_file = sys.argv[2] validate_file(jsonl_file, pubkey_file)Output:
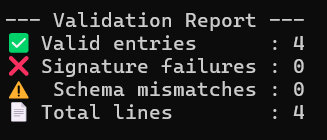
6. Extending This for Real-World AI Workflows
An AI engineer could extend this design in several directions:
-
Neo4j Importer: Build a provenance graph to visualize dataset → model → inference lineage.
-
Metrics integration: Log evaluation metrics (
AUC,F1) into the model record. -
MLOps pipelines: Integrate into training jobs so every experiment auto-generates signed lineage logs.
-
Cloud KMS keys: Replace PEM private key with keys from AWS KMS, GCP KMS, or HashiCorp Vault.
-
Verification service: Deploy a microservice that validates provenance logs on ingestion.
7. Why This Matters for You
As AI systems leave the lab and enter regulated domains (finance, healthcare, insurance), being able to say:
- “This prediction came from Model X at commit Y, trained on Dataset Z, verified cryptographically.”
…will be non-negotiable.
Implementing provenance today sets you ahead of compliance requirements tomorrow.
This ProvenanceTracker is a blueprint for trustworthy AI engineering — versioned, signed, and reproducible lineage for every dataset, model, and inference in your pipeline.
Note: The Customer churn dataset can be downloaded from Kaggle and can be renamed and placed in the data directory.
Related Articles
- Provenance in AI: Auto-Capturing Provenance with MLflow and W3C PROV-O in PyTorch Pipelines – Part 4
Follow for more technical deep dives on AI/ML systems, production engineering, and building real-world applications: