Between March and April 2026, Claude Code got measurably worse. Not because the model changed. Three product-layer modifications stacked on top of each other - a reasoning effort downgrade, a caching bug, and a verbosity cap - degraded output quality for six weeks before Anthropic published a postmortem. The raw API was unaffected the entire time. Engineers running Claude Code CLI felt it as vague inconsistency: more iteration loops, shallower reasoning, outputs that passed type checks but missed the intent of the task.
Most teams had no way to detect this systematically. They felt it. They adjusted prompts. They complained in Slack. They did not know it was a product regression until Anthropic published the postmortem on April 23rd.
Teams that did detect it early had one thing in common: they had defined what good looks like, in testable terms, before the regression arrived. They had workflow-level evals that ran on a schedule. When pass rates dropped, the signal was immediate and specific - not "Claude seems off this week" but "the auth-refactor workflow dropped from 87% to 61% pass rate three days ago."
This is the gap the previous seven articles in this series did not close. The skills article covers skill-level evals - does a single skill produce the right output for a specific prompt? That is necessary. It is not sufficient. Your Claude Code setup is not a collection of isolated skills. It is a system: CLAUDE.md + skills + hooks + subagents + model + Claude Code version, all interacting. When that system degrades - through a model update, a Claude Code release, a skill change, or a CLAUDE.md edit - you need to know before it ships code you did not intend.
This article builds the testing layer for your complete Claude Code setup: what to test, how to write tests that work for agent behavior, how to run them automatically, and how to interpret the results.
Note: This article uses Claude Code as the reference implementation. The testing patterns - workflow-level evals, judge agents, regression baselines, headless execution - apply to any agentic AI system. The specific mechanisms (skill-creator eval format,
claude --headless, MLflow autolog) are Claude Code-specific. The testing philosophy transfers directly to LangSmith evals for LangGraph, Braintrust for OpenAI agents, or any framework that allows headless execution.
Why Skill Evals Are Necessary but Not Sufficient
The skill-creator eval framework, introduced in the Agent Skills article and significantly expanded in the March 2026 skill-creator 2.0 update, gives you a clean testing mechanism for individual skills. You define prompts, describe expected outputs, run with-skill vs without-skill, compare pass rates. It works well for the question: does this skill produce the right output for this category of task?
It does not answer the question every team actually needs answered: does my complete Claude Code setup produce consistently good code across the workflows that matter most to my team?
The gap is systemic. Three failure modes that skill evals cannot catch:
Cross-layer interaction failures - Your verifier skill passes its evals. Your hook correctly blocks rm -rf. Your CLAUDE.md correctly specifies your test runner. But in a real session, the verifier skill triggers before the test runner has been configured, the hook fires at the wrong lifecycle point, and the test that should catch the bug does not run. Each component passed its individual test. The combination failed. You only see this in workflow-level testing.
Model update regressions - Anthropic releases a new Claude Code version or model update. Your skills were written against the previous model's behavior. The new model interprets your skill's instructions differently, activates the wrong skill on ambiguous prompts, or produces outputs that technically match your eval criteria but miss the intent. Skill evals that were passing continue to pass. Workflow quality drops. The regression is in the system, not in any individual component.
Configuration drift - Over three months, five engineers have added entries to CLAUDE.md, two skills have been updated, one hook has been modified, and nobody has run a full workflow test since the initial setup. The configuration has drifted from the state that worked. Something in the accumulated changes interacts badly with something else. The first signal is degraded output on a real task, not a failing test.
These three failure modes require a different testing instrument: the workflow eval - a test that exercises your complete Claude Code setup against a real task and grades the output against defined criteria.
The Testing Pyramid for Claude Code
Software testing has a well-established pyramid: unit tests at the base (fast, many, narrow), integration tests in the middle (slower, fewer, broader), end-to-end tests at the top (slowest, fewest, broadest). Claude Code testing has an equivalent:
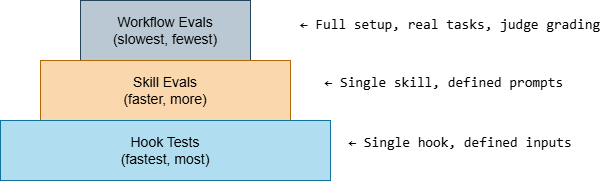
Each layer tests a different scope. All three are necessary. Most teams have only the middle layer (skill evals) if they have any testing at all.
Layer 1: Hook Tests (Fastest - Run on Every Change)
Hooks are shell scripts. Shell scripts are testable with standard shell testing. This is the fastest layer and the most neglected - most teams write hooks and never test them.
The test is simple: pipe a JSON input that should trigger the hook, verify the output is what you expect:
#!/bin/bash# .claude/tests/test-hooks.sh# Run before committing any hook changeset -euo pipefailPASS=0FAIL=0run_test() { local description="$1" local input="$2" local expected_decision="$3" local hook_script="$4" output=$(echo "$input" | bash "$hook_script" 2>/dev/null) decision=$(echo "$output" | jq -r '.hookSpecificOutput.permissionDecision // "allow"') if [ "$decision" = "$expected_decision" ]; then echo " PASS: $description" ((PASS++)) else echo " FAIL: $description (expected=$expected_decision, got=$decision)" ((FAIL++)) fi}echo "=== Hook Tests ==="# block-rm-rf.shecho "--- block-rm-rf ---"run_test "blocks rm -rf /" \ '{"tool_name":"Bash","tool_input":{"command":"rm -rf /"}}' \ "deny" \ ".claude/guards/block-rm-rf.sh"run_test "blocks rm -rf with path" \ '{"tool_name":"Bash","tool_input":{"command":"rm -rf ./dist"}}' \ "deny" \ ".claude/guards/block-rm-rf.sh"run_test "allows safe rm" \ '{"tool_name":"Bash","tool_input":{"command":"rm ./temp.txt"}}' \ "allow" \ ".claude/guards/block-rm-rf.sh"run_test "allows non-bash tool" \ '{"tool_name":"Read","tool_input":{"file_path":"./src/main.ts"}}' \ "allow" \ ".claude/guards/block-rm-rf.sh"# block-force-push.shecho "--- block-force-push ---"run_test "blocks git push --force" \ '{"tool_name":"Bash","tool_input":{"command":"git push --force origin main"}}' \ "deny" \ ".claude/guards/block-force-push.sh"run_test "allows normal push" \ '{"tool_name":"Bash","tool_input":{"command":"git push origin feat/my-branch"}}' \ "allow" \ ".claude/guards/block-force-push.sh"# no-secrets.shecho "--- no-secrets ---"run_test "blocks hardcoded API key" \ '{"tool_name":"Edit","tool_input":{"new_content":"const API_KEY = \"sk-abc123def456ghi789jkl\""}}' \ "deny" \ ".claude/guards/no-secrets.sh"run_test "allows env var reference" \ '{"tool_name":"Edit","tool_input":{"new_content":"const API_KEY = process.env.API_KEY"}}' \ "allow" \ ".claude/guards/no-secrets.sh"echo ""echo "Results: $PASS passed, $FAIL failed"[ "$FAIL" -eq 0 ] && exit 0 || exit 1Run this in a pre-commit hook. Any hook change that breaks an existing test fails the commit. Any new hook gets corresponding tests before it ships.
This is the testing discipline the Hooks article could not prescribe - you could not test hooks in isolation before the article established the hook format. Now that the format exists, tests follow from the format.
Layer 2: Skill Evals (Skill-creator - Run on Skill Changes and Model Updates)
The skill-creator 2.0 framework handles this layer. The key additions from the March 2026 update that make this production-viable:
Parallel eval execution - Evals used to run sequentially, accumulating context between test runs. Now skill-creator spins up independent subagents for each eval, each in a clean context. Cross-contamination between test runs is eliminated. A skill that passes eval 1 cannot leak context into eval 2.
Blind A/B comparators - You can run two skill versions (or skill vs. no skill) against the same inputs. Comparator agents judge outputs without knowing which version produced which result. This eliminates grader bias and gives you a clean signal on whether a skill change actually helped.
Trigger tuning - As your skill count grows, description precision becomes critical. The trigger tuner analyzes your skill description against sample prompts, identifies false positive (skill fires when it should not) and false negative (skill does not fire when it should) patterns, and suggests edits. Anthropic tested this on their own public skills: 5 of 6 document-creation skills showed improvements in activation accuracy after trigger tuning.
The eval format that matters:
{ "skill_name": "pr-reviewer", "evals": [ { "id": "explicit-invocation", "prompt": "Review this PR for security issues before I open it for human review.", "expected": "Produces a structured report with PASS/FAIL verdict, lists security issues by severity with file:line evidence, checks auth bypass, input validation, and error handling.", "should_trigger": true }, { "id": "implicit-invocation", "prompt": "Can you check if this diff looks good before I push?", "expected": "Recognizes as a review request, produces same structured report format.", "should_trigger": true }, { "id": "negative-case", "prompt": "What does our test coverage look like across the codebase?", "expected": "Skill does NOT trigger. This is a coverage question, not a PR review request.", "should_trigger": false }, { "id": "edge-case-empty-diff", "prompt": "Review this PR.", "expected": "Skill triggers, asks for the diff or PR link rather than proceeding without it.", "should_trigger": true } ]}The negative case is as important as the positive cases. A skill that triggers on everything is worse than no skill - it loads irrelevant context and contaminates sessions where it should not be present.
When to run skill evals:
- After any change to a SKILL.md file (immediate)
- After any Claude Code version update (within 24 hours)
- After any model update that changes the default model (within 24 hours)
- On a weekly schedule for capability uplift skills (model progress may have made them obsolete)
Layer 3: Workflow Evals (Full Setup - Run on Schedule and Before Major Changes)
This is the layer that does not exist yet in most teams' Claude Code setups. A workflow eval tests your complete configuration - CLAUDE.md + skills + hooks + subagents - against a realistic task, then grades the output against defined criteria.
The test has three components: a task, a headless execution, and a judge.
flowchart TD
A[Define canonical task\nrealistic, gradeable]:::blue --> B[Headless execution\nclaude --headless\nfull setup runs]:::teal
B --> C[Judge grades output\nLLM rubric\nweighted criteria]:::purple
C --> D{Score vs baseline}:::purple
D -->|Above threshold| E[PASS\nre-baseline if intentional change]:::green
D -->|Below threshold| F[REGRESSION\nSession Reconstruction Loop]:::red
F --> G[Root cause\nCLAUDE.md drift?\nSkill regression?\nModel update?\nHook interaction?]:::yellow
G --> H[Fix targeted layer]:::blue
H --> A
classDef blue fill:#4A90E2,color:#fff,stroke:#3A7BC8
classDef purple fill:#7B68EE,color:#fff,stroke:#6858DE
classDef teal fill:#98D8C8,color:#fff,stroke:#88C8B8
classDef yellow fill:#FFD93D,color:#333,stroke:#EFC92D
classDef green fill:#6BCF7F,color:#fff,stroke:#5BBF6F
classDef red fill:#E74C3C,color:#fff,stroke:#D43C2C
The task: A realistic coding task that exercises the workflows you care about most. Not a trivial task (too easy to pass regardless of configuration quality) and not an impossibly complex one (too hard to grade consistently). A good workflow eval task is something you would actually give Claude during a real session.
Headless execution: Run Claude Code without any interactive input:
# Run a workflow eval headlesslyclaude --headless \ --output-format stream-json \ --print "Refactor the authentication module to use our shared AuthService class. All existing tests must pass. No new dependencies. Run our test suite when done and confirm it passes." \ > .claude/eval-results/auth-refactor-$(date +%Y%m%d-%H%M%S).jsonl--headless mode runs Claude Code non-interactively. --output-format stream-json gives you structured output you can parse. The session runs your complete configuration: CLAUDE.md is loaded, skills trigger on matching content, hooks fire on tool calls, subagents spawn when needed.
The judge: An LLM-graded rubric that evaluates the output:
#!/bin/bash# .claude/tests/workflow-eval.sh# Runs a workflow eval and grades it with a judge agentTASK="${1:-}"EVAL_NAME="${2:-unnamed}"RESULT_FILE=".claude/eval-results/${EVAL_NAME}-$(date +%Y%m%d-%H%M%S).jsonl"# Run the task headlessly, capture all outputecho "Running workflow eval: $EVAL_NAME"claude --headless --output-format stream-json --print "$TASK" > "$RESULT_FILE" 2>&1# Extract the final assistant message (the result)FINAL_OUTPUT=$(cat "$RESULT_FILE" | \ jq -r 'select(.type == "assistant") | .content[] | select(.type == "text") | .text' | \ tail -1)# Extract tool call summary for gradingTOOL_CALLS=$(cat "$RESULT_FILE" | \ jq -r 'select(.type == "tool_use") | "\(.name): \(.input | tostring | .[0:100])"' | \ head -20)# Grade with a judge agentGRADE=$(claude --headless --print "You are grading a Claude Code workflow eval. Grade the following output against the rubric.## Task given to agent$TASK## Tool calls made (sample)$TOOL_CALLS## Final output$FINAL_OUTPUT## RubricScore each criterion 1-5. Return JSON only.{ \"task_completion\": <1-5, did it complete the stated goal?>, \"test_execution\": <1-5, did it run tests and confirm they pass?>, \"code_quality\": <1-5, does the output follow team conventions from CLAUDE.md?>, \"skill_activation\": <1-5, did the right skills trigger for this task type?>, \"no_regressions\": <1-5, does the output avoid breaking existing behavior?>, \"verdict\": \"PASS\" or \"FAIL\", \"weakest_criterion\": \"<which criterion scored lowest>\", \"notes\": \"<one sentence on the most important finding>\"}")echo "$GRADE" | jq '.'# Append to eval historyecho "{\"eval\": \"$EVAL_NAME\", \"date\": \"$(date -u +%Y-%m-%dT%H:%M:%SZ)\", \"grade\": $GRADE}" \ >> .claude/eval-results/history.jsonlThe rubric principle: Write the rubric before you run the eval. The rubric is the specification of what good looks like. If you cannot write the rubric before seeing the output, you do not know what you are testing for. MLflow's engineering team documented this insight precisely: "Write judges before you polish the skill. The judges are the specification. Writing them first forces you to articulate what success actually means."
The Regression Baseline: What Good Looks Like
A single passing eval proves nothing. Quality is relative to a baseline. The regression baseline is the record of what your setup produced on a known-good day, against a fixed set of tasks, at a measured quality level.
Three steps to establish a baseline:
Step 1: Define your canonical task set. Five to ten tasks that represent the most common and most important workflows your team uses Claude Code for. Not all workflows - the ones where quality degradation would hurt most. Auth refactors. API migrations. Test generation for a specific module. PR review for your security checklist.
Step 2: Run the baseline and record scores. Run each task headlessly. Grade each output against its rubric. Record the scores:
{ "date":"2026-04-30", "claude_version":"2.1.116", "eval":"auth-refactor", "scores": { "task_completion":4, "test_execution":5, "code_quality":4, "skill_activation":5, "no_regressions":4 }, "verdict":"PASS", "weighted_score":4.4}{ "date":"2026-04-30", "claude_version":"2.1.116", "eval":"api-migration", "scores":{ "task_completion":5, "test_execution":4, "code_quality":5, "skill_activation":4, "no_regressions":5 }, "verdict":"PASS", "weighted_score":4.6}{ "date":"2026-04-30", "claude_version":"2.1.116", "eval":"security-review", "scores":{ "task_completion":4, "test_execution":3, "code_quality":4, "skill_activation":5, "no_regressions":4 }, "verdict":"PASS", "weighted_score":4.0}Step 3: Set your alert threshold. A drop of more than 0.5 on any individual criterion, or more than 0.3 on the weighted average, triggers investigation. Not automatic revert - investigation. Some drops are expected after intentional configuration changes. The baseline tells you the drop happened. Investigation tells you whether it should have.
When to re-baseline:
- After intentional CLAUDE.md changes that you expect to improve quality
- After a skill update that passed its skill evals
- After a Claude Code major version update where the quality delta is positive
Do not re-baseline after a Claude Code update until you have investigated the quality delta. If the new version is better, re-baseline at the new level. If it is worse, pin the previous version and file a report.
Running Tests on a Schedule: The Automated Regression Guard
Hook tests run on every commit via pre-commit. Skill evals run manually on skill changes and model updates. Workflow evals need to run on a schedule - because the configuration can regress without any file in the repo changing, as the April 2026 incident demonstrated.
A GitHub Action that runs weekly:
# .github/workflows/claude-code-regression.ymlname: Claude Code Regression Guardon: schedule: - cron: '0 9 * * 1' # Every Monday 9am UTC workflow_dispatch: # Manual trigger for immediate check after updatesjobs: regression-check: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - name: Install Claude Code run: npm install -g @anthropic-ai/claude-code - name: Run hook tests run: bash .claude/tests/test-hooks.sh - name: Run workflow evals env: ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }} run: | bash .claude/tests/workflow-eval.sh \ "Refactor the auth module to use AuthService. Run tests." \ "auth-refactor" bash .claude/tests/workflow-eval.sh \ "Review the latest diff for security issues." \ "security-review" - name: Check for regression run: | python3 .claude/tests/check-regression.py \ --history .claude/eval-results/history.jsonl \ --threshold 0.3 - name: Alert on regression if: failure() uses: actions/github-script@v7 with: script: | github.rest.issues.create({ owner: context.repo.owner, repo: context.repo.repo, title: 'Claude Code regression detected - ' + new Date().toISOString().split('T')[0], body: 'Workflow eval scores dropped below threshold. Check .claude/eval-results/history.jsonl for details.', labels: ['claude-code', 'regression'] })# .claude/tests/check-regression.pyimport jsonimport sysimport argparsedef check_regression(history_file: str, threshold: float): with open(history_file) as f: history = [json.loads(line) for line in f if line.strip()] if len(history) < 2: print("Not enough history to detect regression") sys.exit(0) # Group by eval name by_eval = {} for entry in history: name = entry["eval"] if name not in by_eval: by_eval[name] = [] by_eval[name].append(entry) regressions = [] for eval_name, entries in by_eval.items(): if len(entries) < 2: continue entries.sort(key=lambda x: x["date"]) baseline = entries[-2]["grade"]["weighted_score"] current = entries[-1]["grade"]["weighted_score"] drop = baseline - current if drop > threshold: regressions.append({ "eval": eval_name, "baseline": baseline, "current": current, "drop": drop }) if regressions: print(f"REGRESSION DETECTED in {len(regressions)} eval(s):") for r in regressions: print(f" {r['eval']}: {r['baseline']:.2f} → {r['current']:.2f} (drop: {r['drop']:.2f})") sys.exit(1) else: print("No regression detected") sys.exit(0)This is the detection layer that would have caught the April 2026 regression in three days instead of six weeks. The Monday run after the Claude Code update would have shown the drop. The issue would have been filed. Teams would have known to pin the previous version while investigating.
The Wrong Way: Testing By Feel
Here is the pattern most teams follow. A new engineer joins and asks "how do we know our Claude Code setup is working?" The answer is "it works well for us, we use it every day."
# The implicit test suite most teams are running:# 1. Use Claude Code on real tasks# 2. Notice when something seems off# 3. Try tweaking the prompt or skill# 4. Continue if the next output seems better# This is not testing. This is hoping.# It catches obvious failures. It misses:# - Subtle quality degradation that accumulates over weeks# - Regressions that only affect specific task types you have not happened to run recently# - Cross-layer interaction failures that only surface on complex tasks# - Configuration drift where individual changes each seem fine but combine badlyThe April 2026 regression was subtle enough that most teams did not detect it through normal usage for three weeks. They felt vague inconsistency. They attributed it to task complexity or prompt quality. They adjusted. They adapted. They compensated for a product regression by working harder.
Teams with workflow evals caught it in seventy-two hours.
The Right Way: The Eval-Fix-Verify Loop
Once you have the testing pyramid in place, every configuration change follows the same discipline:
1. Before changing anything: Run your canonical task set. Record the current scores. This is your before state.
2. Make the change: Edit CLAUDE.md, update a skill, modify a hook, pin a Claude Code version.
3. Run the relevant layer:
- Hook change → run hook tests immediately
- Skill change → run skill evals for that skill
- CLAUDE.md change → run workflow evals for affected task types
- Claude Code version update → run the full canonical task set
4. Compare to before state: Did scores improve, stay the same, or drop? If they dropped: is the drop expected (you intentionally narrowed behavior) or unexpected (the change had a side effect)?
5. If unexpected drop: Use the Session Reconstruction Loop from the Observability article. Reconstruct the failing session timeline. Identify the divergence point. Find the root cause. Fix it. Re-test.
6. If expected improvement: Re-baseline. The new scores become your new floor.
This loop is the Spec-Eval-Verify Cycle - the discipline that turns "I think this change is better" into "this change improved the auth-refactor eval from 4.2 to 4.7 and did not regress any other eval." It is the difference between configuration management by feel and configuration management by evidence.
What the Complete Test Run Looks Like
For a team that has implemented all three layers:
# Pre-commit (runs on every git commit, <30 seconds)bash .claude/tests/test-hooks.sh# Skill change (runs when any SKILL.md changes, <5 minutes per skill)claude "evaluate my pr-reviewer skill" # skill-creator eval mode# Weekly automated (runs every Monday, ~20 minutes for 5 workflow evals)# Triggered by GitHub Action, results in eval-results/history.jsonl# Before a Claude Code version update (manual, ~20 minutes)CLAUDE_CODE_VERSION=2.1.116 bash .claude/tests/run-canonical-suite.sh# After a Claude Code version update (manual, ~20 minutes)CLAUDE_CODE_VERSION=2.2.0 bash .claude/tests/run-canonical-suite.sh# Compare resultspython3 .claude/tests/check-regression.py \ --history .claude/eval-results/history.jsonl \ --threshold 0.3Total weekly cost: one automated GitHub Action run, approximately $0.40-0.80 in API costs for five workflow evals. In exchange: a systematic detection layer that catches regressions before they ship code, a baseline that makes every configuration change defensible, and an audit trail that shows exactly when and how quality changed.
Production Checklist: Testing Your Claude Code Setup
Hook tests (every project)
- Every hook in
.claude/guards/has corresponding tests in.claude/tests/test-hooks.sh - Tests cover both the positive case (hook blocks what it should) and negative cases (hook allows what it should not block)
- Hook tests run in pre-commit via a git hook
- Any new hook requires passing tests before it is merged
Skill evals (every skill)
- Every skill in use has at least 10 eval cases: explicit invocation, implicit invocation, negative cases (should not trigger), edge cases
- Evals run in parallel (skill-creator 2.0 multi-agent mode) not sequentially
- Baseline pass rate recorded per skill per Claude Code version
- Evals scheduled to run after any Claude Code or model update
Workflow evals (canonical task set)
- 5-10 canonical tasks defined representing your most important workflows
- Each task has a written rubric before the first eval run
- Baseline scores recorded for current Claude Code version
- Regression threshold set (recommended: 0.3 weighted average drop)
- GitHub Action or equivalent runs canonical suite on a weekly schedule
- Results stored in queryable format (JSONL) with Claude Code version and date
Regression response
- On detected regression: first check Claude Code version against known-good baseline
- Before pinning a version: confirm the regression is in the product layer not the task (test raw API against same prompt)
- After Anthropic resolves a regression: re-run canonical suite before unpinning
- Every regression investigation added to
.claude/audit.jsonlwith root cause and resolution
References
- Build This Now. (April 2026). Claude Code Quality Regression: What Actually Happened. https://www.buildthisnow.com/blog/models/claude-code-quality-regression-2026
- Anthropic. (April 23, 2026). April 23 postmortem - Claude Code reasoning quality regression. https://www.anthropic.com/engineering/april-23-postmortem
- Anthropic. (March 2026). Improving skill-creator: Test, measure, and refine Agent Skills. https://claude.com/blog/improving-skill-creator-test-measure-and-refine-agent-skills
- Pillitteri, P. (March 2026). Claude Code Skills 2.0: Evals, Benchmarks and A/B Testing for Skills that Actually Work. https://pasqualepillitteri.it/en/news/341/claude-code-skills-2-0-evals-benchmarks-guide
- MLflow. (March 2026). Testing and Refining Claude Code Skills with MLflow. https://mlflow.org/blog/evaluating-skills-mlflow/
- MindStudio. (March 2026). How to Use Claude Code Skills 2.0: Built-In Evaluation and A/B Testing for AI Workflows. https://www.mindstudio.ai/blog/claude-code-skills-2-evaluation-ab-testing
- Hightower, R. (March 2026). Claude Code: How to Build, Evaluate, and Tune AI Agent Skills. Towards AI. https://medium.com/@richardhightower/claude-code-how-to-build-evaluate-and-tune-ai-agent-skills-34afa808d1c9
- Fireworks AI. (August 2025). LLM Eval Driven Development with Claude Code. https://fireworks.ai/blog/eval-driven-development-with-claude-code
- Anthropic / Claude API Docs. Define success criteria and build evaluations. https://platform.claude.com/docs/en/test-and-evaluate/develop-tests
- Anthropic / Claude Code Docs. Code Review - managed multi-agent PR analysis. https://code.claude.com/docs/en/code-review
Related Articles
- Agent Skills Are Not Prompts. They Are Production Knowledge Infrastructure.
- Which Claude Code Layer Solves Your Problem? A Diagnostic Guide for AI Engineers
- You Can't Debug What You Can't See: Observability for Claude Code Sessions
- Hooks: The Enforcement Layer That Turns Agent Policy Into Agent Fact